## Chart Type: Multiple Line Charts Comparing Sentence Probabilities
### Overview
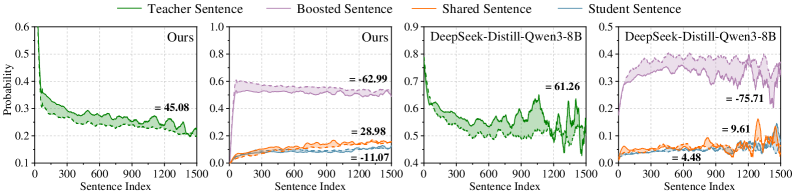
The image presents four line charts arranged horizontally, comparing the probabilities of different sentence types (Teacher, Boosted, Shared, and Student) across a range of sentence indices. Each chart represents a different model or configuration ("Ours" and "DeepSeek-Distill-Qwen3-8B"). The charts show how the probability of each sentence type changes as the sentence index increases.
### Components/Axes
* **X-axis (all charts):** "Sentence Index" ranging from 0 to 1500 in increments of 300.
* **Y-axis (all charts):** "Probability" ranging from 0.1 to 0.6 (first chart), 0.0 to 1.0 (second chart), 0.4 to 0.9 (third chart), and 0.0 to 0.5 (fourth chart).
* **Legends (top of the image):**
* Green: "Teacher Sentence"
* Purple: "Boosted Sentence"
* Orange: "Shared Sentence"
* Blue: "Student Sentence"
* **Chart Titles (above each chart):**
* Chart 1: "Ours"
* Chart 2: "Ours"
* Chart 3: "DeepSeek-Distill-Qwen3-8B"
* Chart 4: "DeepSeek-Distill-Qwen3-8B"
### Detailed Analysis
**Chart 1: Ours**
* **Teacher Sentence (Green):** The probability starts around 0.4 and generally decreases to approximately 0.2 over the sentence index range. There are fluctuations, but the overall trend is downward.
* Value at Sentence Index 1200: ~0.25
* Value at Sentence Index 1500: ~0.20
* Text Annotation: "= 45.08" located near the right side of the chart.
**Chart 2: Ours**
* **Boosted Sentence (Purple):** The probability starts around 0.55-0.6 and remains relatively stable across the sentence index range.
* Value at Sentence Index 0: ~0.55
* Value at Sentence Index 1500: ~0.55
* Text Annotation: "= -62.99" located near the right side of the chart.
* **Shared Sentence (Orange):** The probability starts near 0 and increases to approximately 0.15.
* Value at Sentence Index 0: ~0.0
* Value at Sentence Index 1500: ~0.15
* Text Annotation: "= 28.98" located near the right side of the chart.
* **Student Sentence (Blue):** The probability starts near 0 and increases to approximately 0.1.
* Value at Sentence Index 0: ~0.0
* Value at Sentence Index 1500: ~0.1
* Text Annotation: "= -11.07" located near the right side of the chart.
**Chart 3: DeepSeek-Distill-Qwen3-8B**
* **Teacher Sentence (Green):** The probability starts high, around 0.8, and decreases rapidly before fluctuating between 0.5 and 0.6.
* Value at Sentence Index 0: ~0.8
* Value at Sentence Index 1500: ~0.55
* Text Annotation: "= 61.26" located near the right side of the chart.
**Chart 4: DeepSeek-Distill-Qwen3-8B**
* **Boosted Sentence (Purple):** The probability starts low, around 0.25, and increases to approximately 0.35.
* Value at Sentence Index 0: ~0.25
* Value at Sentence Index 1500: ~0.35
* Text Annotation: "= -75.71" located near the right side of the chart.
* **Shared Sentence (Orange):** The probability starts near 0 and increases to approximately 0.1.
* Value at Sentence Index 0: ~0.0
* Value at Sentence Index 1500: ~0.1
* Text Annotation: "= 9.61" located near the right side of the chart.
* **Student Sentence (Blue):** The probability starts near 0 and increases to approximately 0.05.
* Value at Sentence Index 0: ~0.0
* Value at Sentence Index 1500: ~0.05
* Text Annotation: "= 4.48" located near the right side of the chart.
### Key Observations
* The "Ours" model shows a decreasing probability for "Teacher Sentence" as the sentence index increases, while the "Boosted Sentence" probability remains relatively stable.
* The "DeepSeek-Distill-Qwen3-8B" model shows a decreasing probability for "Teacher Sentence" and an increasing probability for "Boosted Sentence" as the sentence index increases.
* The "Shared Sentence" and "Student Sentence" probabilities are generally low for both models, with a slight increase as the sentence index increases.
* The text annotations on each chart appear to represent some form of score or metric associated with the model and sentence type.
### Interpretation
The charts compare the performance of two models ("Ours" and "DeepSeek-Distill-Qwen3-8B") in terms of sentence type probabilities across a range of sentence indices. The data suggests that the models handle different sentence types differently. For example, the "Ours" model seems to favor "Teacher Sentences" initially, but this preference decreases over the sentence index. In contrast, the "DeepSeek-Distill-Qwen3-8B" model shows an increasing preference for "Boosted Sentences." The low probabilities for "Shared Sentence" and "Student Sentence" across both models might indicate that these sentence types are less common or more difficult to predict. The text annotations likely represent a quantitative measure of the model's performance or bias towards each sentence type, providing a more precise comparison of the models' behavior.