## Line Chart: Scaling Laws: First Pit
### Overview
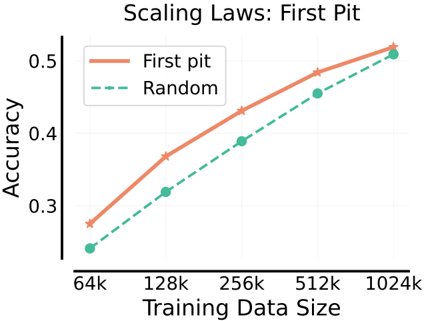
The image is a line chart comparing the accuracy of two methods, "First pit" and "Random," against the size of the training data. The x-axis represents the training data size, ranging from 64k to 1024k, while the y-axis represents accuracy, ranging from 0.3 to 0.5.
### Components/Axes
* **Title:** Scaling Laws: First Pit
* **X-axis Title:** Training Data Size
* **X-axis Markers:** 64k, 128k, 256k, 512k, 1024k
* **Y-axis Title:** Accuracy
* **Y-axis Markers:** 0.3, 0.4, 0.5
* **Legend:** Located in the top-left corner.
* **First pit:** Represented by a solid coral line with star markers.
* **Random:** Represented by a dashed teal line with circle markers.
### Detailed Analysis
* **First pit:** The coral line with star markers.
* At 64k training data size, the accuracy is approximately 0.27.
* At 128k training data size, the accuracy is approximately 0.37.
* At 256k training data size, the accuracy is approximately 0.43.
* At 512k training data size, the accuracy is approximately 0.49.
* At 1024k training data size, the accuracy is approximately 0.52.
* The trend is upward, indicating increasing accuracy with larger training data sizes.
* **Random:** The dashed teal line with circle markers.
* At 64k training data size, the accuracy is approximately 0.24.
* At 128k training data size, the accuracy is approximately 0.32.
* At 256k training data size, the accuracy is approximately 0.39.
* At 512k training data size, the accuracy is approximately 0.46.
* At 1024k training data size, the accuracy is approximately 0.51.
* The trend is upward, indicating increasing accuracy with larger training data sizes.
### Key Observations
* Both methods, "First pit" and "Random," show an increase in accuracy as the training data size increases.
* The "First pit" method consistently outperforms the "Random" method across all training data sizes.
* The gap in accuracy between the two methods appears to narrow slightly as the training data size increases, but "First pit" maintains a higher accuracy.
* Both lines appear to be approaching an asymptote as the training data size increases to 1024k.
### Interpretation
The data suggests that the "First pit" method is more effective than the "Random" method for this particular task, as it achieves higher accuracy across all tested training data sizes. The positive correlation between training data size and accuracy for both methods indicates that increasing the amount of training data generally improves performance. The narrowing gap between the two methods at larger training data sizes could suggest that the "Random" method benefits more from increased data, or that both methods are approaching a performance ceiling. Further investigation with even larger training datasets would be needed to confirm this.