## Line Chart: Scaling Laws: First Pit
### Overview
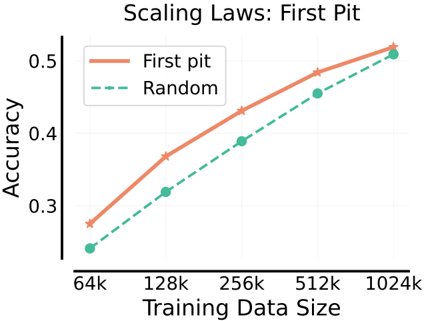
The chart illustrates the relationship between training data size and accuracy for two methods: "First pit" and "Random." Accuracy increases with larger training data sizes, with "First pit" consistently outperforming "Random" across all data sizes.
### Components/Axes
- **X-axis (Training Data Size)**: Labeled with values 64k, 128k, 256k, 512k, and 1024k (in thousands).
- **Y-axis (Accuracy)**: Ranges from 0.25 to 0.5 in increments of 0.05.
- **Legend**: Located in the top-left corner, with:
- Solid orange line: "First pit"
- Dashed green line: "Random"
- **Data Points**: Marked with stars (First pit) and circles (Random).
### Detailed Analysis
- **First pit (Orange Solid Line)**:
- Starts at ~0.25 accuracy at 64k data points.
- Increases to ~0.35 at 128k, ~0.42 at 256k, ~0.48 at 512k, and ~0.52 at 1024k.
- **Random (Dashed Green Line)**:
- Starts at ~0.22 accuracy at 64k.
- Increases to ~0.32 at 128k, ~0.38 at 256k, ~0.45 at 512k, and ~0.5 at 1024k.
### Key Observations
1. **Performance Gap**: "First pit" maintains a ~0.03–0.05 accuracy advantage over "Random" at all data sizes.
2. **Scaling Efficiency**: Both methods show linear growth, but "First pit" demonstrates steeper improvement, especially between 256k and 1024k.
3. **Convergence**: At 1024k, the gap narrows to ~0.02, suggesting diminishing returns for "First pit" at very large data sizes.
### Interpretation
The data suggests that the "First pit" method is more effective than random selection for improving accuracy, particularly in low-data regimes. However, as training data scales to 1M+ points, the performance advantage of "First pit" diminishes, indicating that random methods may become more competitive with sufficient data. This aligns with scaling laws principles, where algorithmic efficiency gains plateau as data size increases. The chart underscores the importance of method selection in resource-constrained scenarios but highlights that data quantity alone cannot fully compensate for suboptimal algorithms.