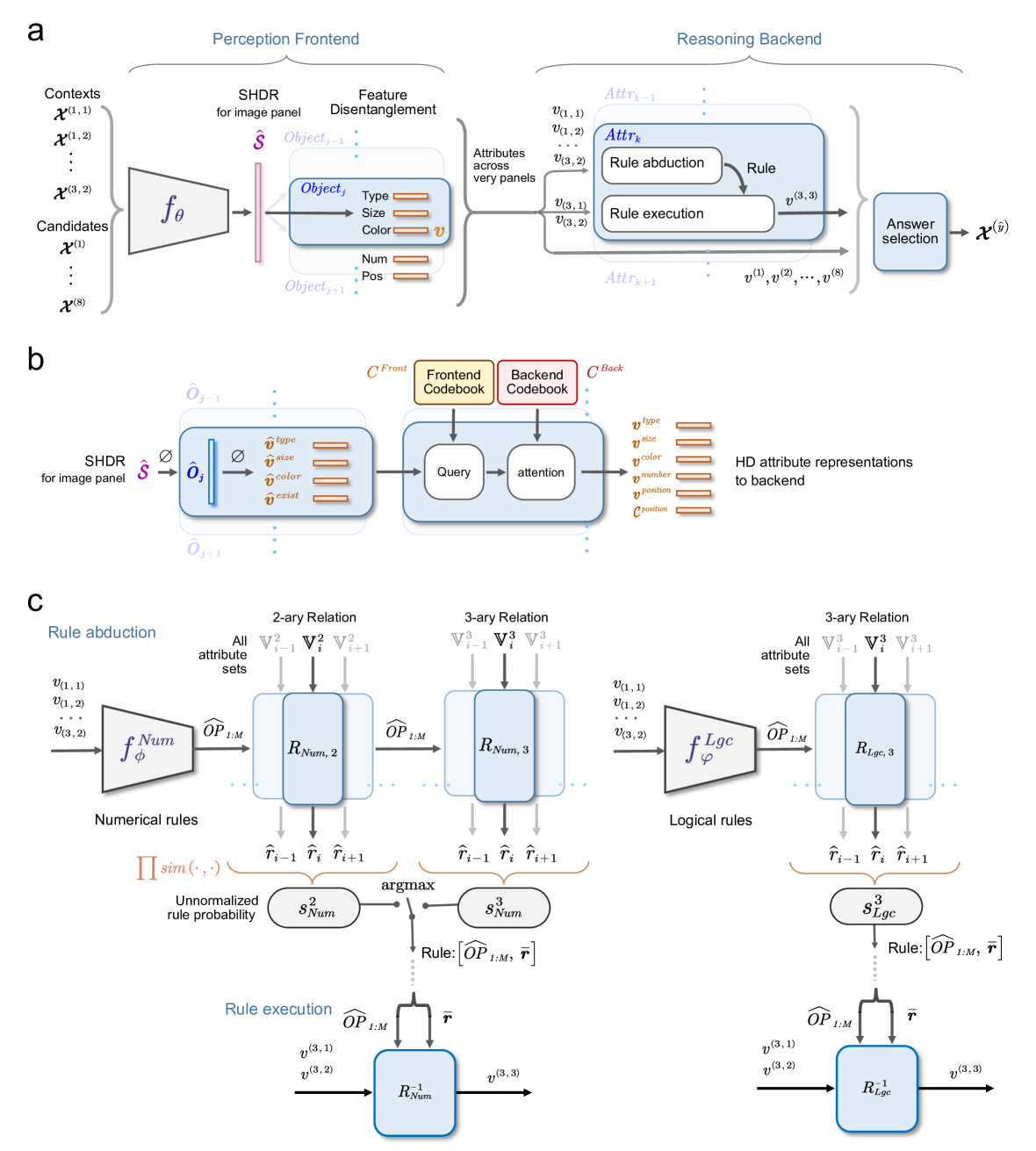
## Hybrid Perception and Reasoning System Diagram
### Overview
The image presents a diagram illustrating a hybrid perception and reasoning system, divided into a "Perception Frontend" and a "Reasoning Backend." It details the flow of information from input contexts and candidates, through feature disentanglement and rule-based reasoning, to final answer selection. The diagram includes components for SHDR (for image panel), feature disentanglement, attribute processing, rule abduction, and rule execution, with both numerical and logical rule paths.
### Components/Axes
**Overall Structure:**
* The diagram is split horizontally into three sections, labeled a, b, and c.
* Section a shows the high-level flow from perception to reasoning.
* Section b details the SHDR processing and codebook lookup.
* Section c elaborates on the rule abduction and execution processes.
**Section a: Perception Frontend and Reasoning Backend**
* **Title:** "Perception Frontend" (left), "Reasoning Backend" (right)
* **Input:**
* "Contexts": x^(1,1), x^(1,2), ..., x^(3,2)
* "Candidates": x^(1), ..., x^(8)
* **Perception Frontend Components:**
* "SHDR for image panel": Ŝ
* Function: f_θ
* "Feature Disentanglement":
* "Object_j-1":
* "Object_j":
* "Type"
* "Size"
* "Color": v
* "Num"
* "Pos"
* "Object_j+1"
* **Reasoning Backend Components:**
* "Attributes across very panels":
* "Attr_k-1"
* v^(1,1), v^(1,2), v^(3,2)
* "Attr_k":
* "Rule abduction"
* "Rule"
* "Attr_k+1"
* v^(3,1), v^(3,2)
* "Rule execution"
* "Answer selection": x^(y)
* Input to Answer Selection: v^(1), v^(2), ..., v^(8)
**Section b: SHDR Processing and Codebook Lookup**
* "SHDR for image panel": Ŝ
* Input: O_j-1
* Processing: Ø
* Output: Ô_j
* Attribute Vectors:
* v^type
* v^size
* v^color
* v^exist
* Output: O_j+1
* Codebooks:
* "C^Front Frontend Codebook": Yellow box
* "C^Back Backend Codebook": Red box
* "Query" -> "attention"
* HD attribute representations to backend:
* v^type
* v^size
* v^color
* v^number
* v^position
**Section c: Rule Abduction and Execution**
* **Left Side: Numerical Rules**
* "Rule abduction"
* Input: v^(1,1), v^(1,2), ..., v^(3,2)
* Function: f_Num φ
* Operator: OP_1:M
* "2-ary Relation": R_Num,2
* All attribute sets: V^2_i-1, V^2_i, V^2_i+1
* "3-ary Relation": R_Num,3
* All attribute sets: V^3_i-1, V^3_i, V^3_i+1
* Outputs: r̂_i-1, r̂_i, r̂_i+1
* "Unnormalized rule probability": Π sim(.,.)
* "argmax": s^2_Num, s^3_Num
* "Rule": [OP_1:M, r]
* "Rule execution"
* Input: v^(3,1), v^(3,2)
* Operator: OP_1:M
* Output: v^(3,3)
* Relation: R^-1_Num
* **Right Side: Logical Rules**
* "Rule abduction"
* Input: v^(1,1), v^(1,2), ..., v^(3,2)
* Function: f_Lgc φ
* Operator: OP_1:M
* "3-ary Relation": R_Lgc,3
* All attribute sets: V^3_i-1, V^3_i, V^3_i+1
* Outputs: r̂_i-1, r̂_i, r̂_i+1
* "argmax": s^3_Lgc
* "Rule": [OP_1:M, r]
* "Rule execution"
* Input: v^(3,1), v^(3,2)
* Operator: OP_1:M
* Output: v^(3,3)
* Relation: R^-1_Lgc
### Detailed Analysis or ### Content Details
* **Perception Frontend:** The system takes contexts and candidates as input. The SHDR module processes the image panel, and feature disentanglement extracts object attributes like type, size, color, number, and position.
* **Reasoning Backend:** Attributes are processed through rule abduction and execution. The system uses both numerical and logical rules. The final step is answer selection.
* **SHDR Processing:** The SHDR module transforms the input image panel through a series of operations (represented by Ø) to produce an output. This output is then used to query frontend and backend codebooks.
* **Rule Processing:** Rule abduction uses functions (f_Num and f_Lgc) and operators (OP_1:M) to process attribute sets. The argmax function selects the best rule based on unnormalized rule probabilities. Rule execution then applies the selected rule to produce the final output.
### Key Observations
* The system is designed to integrate perception and reasoning.
* Feature disentanglement is a key step in extracting relevant attributes.
* Both numerical and logical rules are used in the reasoning process.
* The system uses codebooks to map attributes to representations.
### Interpretation
The diagram illustrates a sophisticated AI system that combines perception and reasoning to solve complex tasks. The system first extracts relevant features from the input image using the Perception Frontend. These features are then used by the Reasoning Backend to apply rules and select the best answer. The use of both numerical and logical rules allows the system to handle a wide range of reasoning tasks. The codebooks provide a way to map attributes to representations, which is important for generalization and transfer learning. The diagram highlights the key components and flow of information in the system, providing a valuable overview of its architecture and functionality.