\n
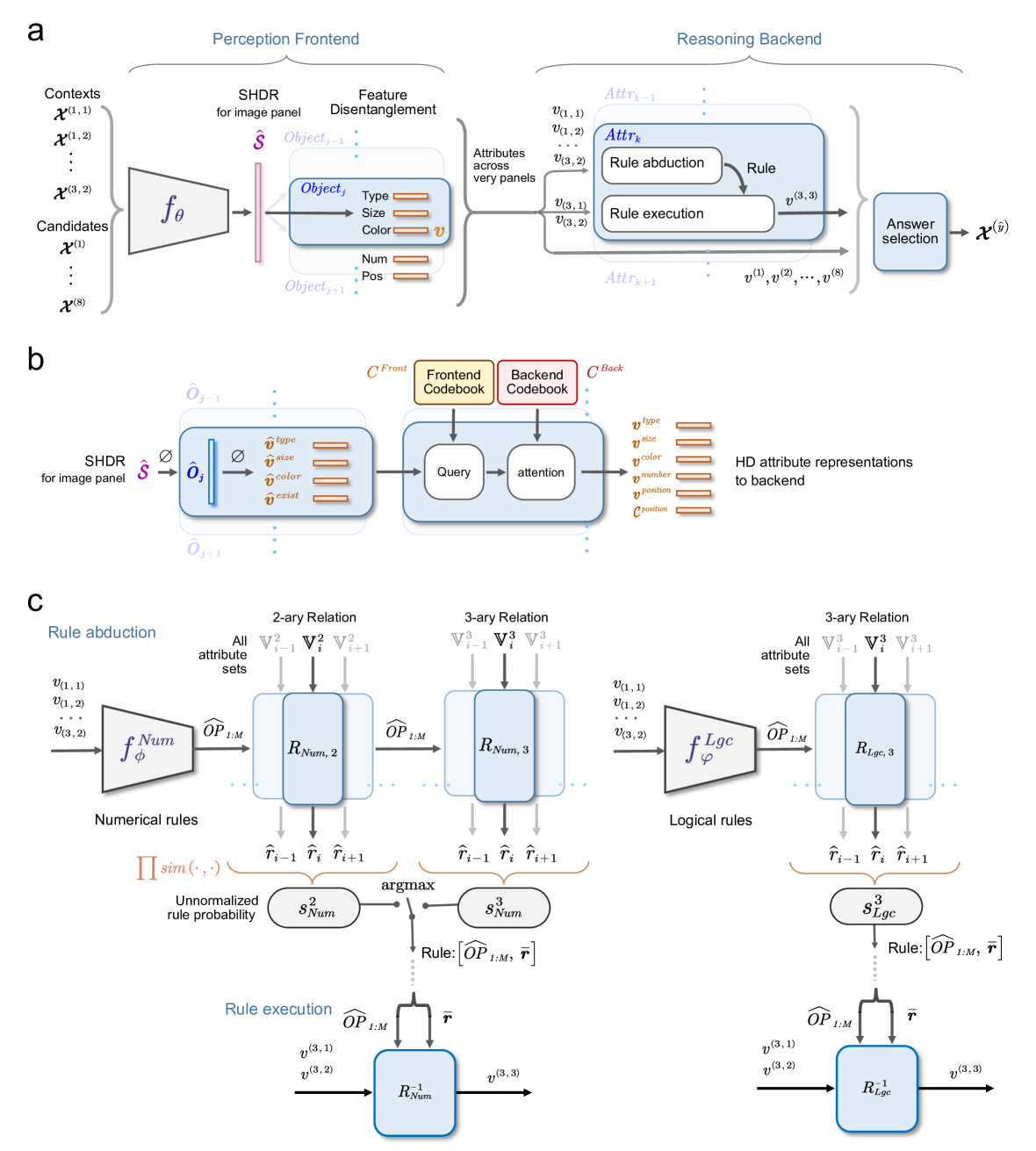
## Diagram: Visual Reasoning Framework
### Overview
This diagram illustrates a visual reasoning framework composed of a Perception Frontend and a Reasoning Backend. The framework takes visual contexts as input, processes them to extract attributes, and then applies rules to arrive at an answer. The diagram is divided into three sections (a, b, and c) that detail the different stages of the process.
### Components/Axes
The diagram consists of several key components:
* **Perception Frontend:** Includes "Contexts" (x<sup>(1,1)</sup>, x<sup>(1,2)</sup>, x<sup>(1,3)</sup>), "Candidates" (x<sup>(6)</sup>), "SHDR" (Scene Hierarchy Directed Relational), "Feature Disentanglement", and "Object" (with attributes: Type, Size, Color, Num, Pos).
* **Reasoning Backend:** Includes "Attributes" (v<sub>1,1</sub>, v<sub>1,2</sub>, v<sub>1,3</sub>), "Rule Abduction", "Rule Execution", and "Answer Selection" (x<sup>(7)</sup>).
* **Codebooks:** "Frontend Codebook" (C<sub>Front</sub>) and "Backend Codebook" (C<sub>Back</sub>).
* **Rule Abduction:** Depicts both "Numerical Rules" and "Logical Rules" with associated operations and probabilities.
* **Attribute Sets:** Represented as V<sup>2</sup> and V<sup>3</sup> for 2-ary and 3-ary relations respectively.
### Detailed Analysis or Content Details
**Section a: Overall Framework**
* **Input:** Contexts x<sup>(1,1)</sup>, x<sup>(1,2)</sup>, x<sup>(1,3)</sup> are fed into a function *f<sub>θ</sub>* which outputs Objects.
* **Object Attributes:** Objects are characterized by attributes: Type, Size, Color, Num, Pos. These are then passed to the Reasoning Backend as Attributes v<sub>1,1</sub>, v<sub>1,2</sub>, v<sub>1,3</sub>.
* **Rule Application:** The Reasoning Backend uses Rule Abduction and Rule Execution to generate an answer y<sup>(3)</sup>, which is then used for Answer Selection x<sup>(7)</sup>.
* **SHDR:** The diagram indicates that SHDR is used "for image panel representation".
**Section b: Codebook and Attention Mechanism**
* **SHDR Output:** The SHDR outputs object representations (ô<sub>1,1</sub>).
* **Frontend Codebook:** The Frontend Codebook (C<sub>Front</sub>) maps object attributes (type, size, color, count, position) to representations.
* **Query & Attention:** A "Query" is used with an "attention" mechanism to process the object representations.
* **Backend Codebook:** The Backend Codebook (C<sub>Back</sub>) maps HD attribute representations to the backend.
**Section c: Rule Abduction and Execution**
* **Numerical Rules:**
* Input: Attributes v<sub>1,1</sub>, v<sub>1,2</sub>, v<sub>1,3</sub>.
* Operation: f<sup>Num</sup> and OP<sub>1,M</sub>.
* Relation: R<sub>Num,2</sub> and R<sub>Num,3</sub>.
* Probability: ∏ sin(·) and argmax (with denominator 8 * Num).
* Output: y<sup>(3),2</sup> and y<sup>(3),3</sup>.
* **Logical Rules:**
* Input: Attributes v<sub>1,1</sub>, v<sub>1,2</sub>, v<sub>1,3</sub>.
* Operation: f<sup>Lgc</sup> and OP<sub>1,M</sub>.
* Relation: R<sub>Lgc,2</sub> and R<sub>Lgc,3</sub>.
* Probability: 3 * Lgc.
* Output: y<sup>(3),2</sup> and y<sup>(3),3</sup>.
* **Rule Execution:** Both numerical and logical rules lead to Rule Execution, resulting in outputs y<sup>(3),2</sup> and y<sup>(3),3</sup>.
### Key Observations
* The framework explicitly separates perception and reasoning.
* The use of codebooks suggests a learned representation of objects and attributes.
* The rule abduction process involves both numerical and logical reasoning.
* Probabilistic elements are incorporated into the rule abduction process.
* The diagram highlights the flow of information from visual contexts to a final answer.
### Interpretation
This diagram presents a sophisticated visual reasoning system. The Perception Frontend aims to extract meaningful attributes from visual input, while the Reasoning Backend leverages these attributes to apply predefined rules and derive conclusions. The use of SHDR suggests a hierarchical understanding of scenes. The separation of numerical and logical rules indicates the system can handle different types of reasoning. The probabilistic nature of rule abduction suggests the system can deal with uncertainty and ambiguity. The attention mechanism in Section b likely allows the system to focus on relevant parts of the image when applying rules.
The diagram suggests a system capable of complex visual problem-solving, potentially applicable to tasks like visual question answering or robotic navigation. The framework's modularity allows for independent improvement of the perception and reasoning components. The inclusion of codebooks implies that the system learns to represent visual concepts in a way that facilitates reasoning. The overall architecture is designed to mimic human cognitive processes, combining perception, knowledge representation, and logical inference.