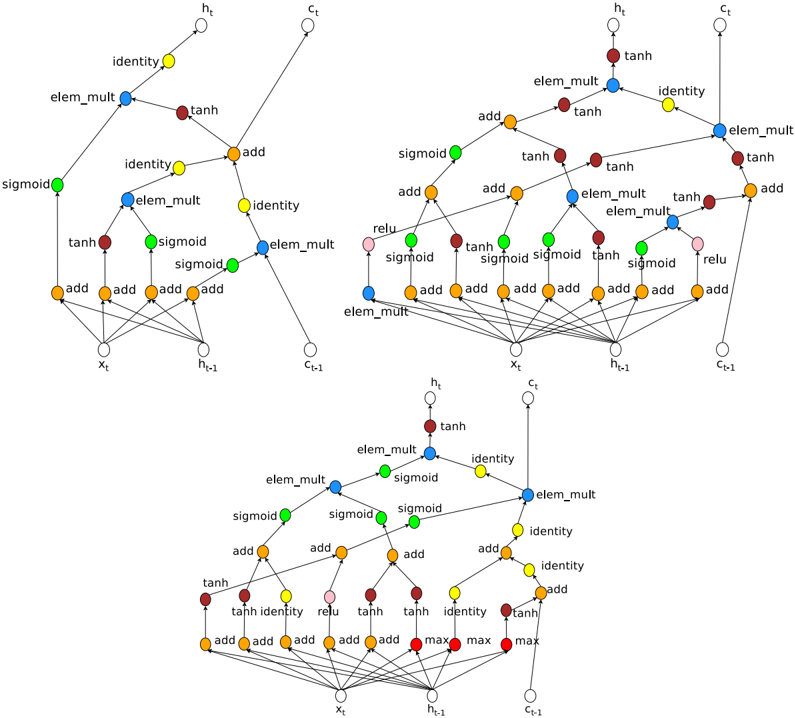
## Diagram: Recurrent Neural Network Cell Variations
### Overview
The image presents three variations of a recurrent neural network (RNN) cell, likely Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) cells, visualized as computational graphs. Each cell takes inputs *x<sub>t</sub>*, *h<sub>t-1</sub>*, and *c<sub>t-1</sub>* and produces outputs *h<sub>t</sub>* and *c<sub>t</sub>*. The diagrams illustrate the flow of data through different operations within each cell, such as sigmoid, tanh, element-wise multiplication (elem_mult), and addition (add).
### Components/Axes
Each cell diagram contains the following components:
* **Inputs:**
* *x<sub>t</sub>*: Input at time *t*.
* *h<sub>t-1</sub>*: Hidden state at time *t-1*.
* *c<sub>t-1</sub>*: Cell state at time *t-1*.
* **Outputs:**
* *h<sub>t</sub>*: Hidden state at time *t*.
* *c<sub>t</sub>*: Cell state at time *t*.
* **Operations:**
* `sigmoid`: Sigmoid activation function. Represented by green nodes.
* `tanh`: Hyperbolic tangent activation function. Represented by brown/dark red nodes.
* `elem_mult`: Element-wise multiplication. Represented by blue nodes.
* `add`: Addition. Represented by orange nodes.
* `identity`: Identity function. Represented by yellow nodes.
* `relu`: Rectified Linear Unit activation function. Represented by pink nodes.
* `max`: Maximum function. Represented by red nodes.
### Detailed Analysis
**Cell 1 (Top-Left)**
* Input *x<sub>t</sub>* is fed into three `add` operations.
* Input *h<sub>t-1</sub>* is fed into three `add` operations.
* The outputs of these `add` operations are then passed through `tanh`, `sigmoid`, and `sigmoid` activations (green, brown, green).
* The outputs of the `tanh` and `sigmoid` activations are combined using `elem_mult` (blue).
* The output of the `elem_mult` is then passed through an `identity` function (yellow) to produce *h<sub>t</sub>*.
* Input *c<sub>t-1</sub>* is passed through an `identity` function (yellow) and then combined with the output of another `elem_mult` (blue) via an `add` operation (orange).
* The output of this `add` operation is passed through an `identity` function (yellow) to produce *c<sub>t</sub>*.
**Cell 2 (Top-Right)**
* Input *x<sub>t</sub>* is fed into four `add` operations.
* Input *h<sub>t-1</sub>* is fed into four `add` operations.
* The outputs of these `add` operations are then passed through `tanh`, `sigmoid`, `sigmoid`, and `tanh` activations (brown, green, green, brown).
* Input *c<sub>t-1</sub>* is fed into four `add` operations.
* The outputs of these `add` operations are then passed through `relu`, `sigmoid`, `sigmoid`, and `relu` activations (pink, green, green, pink).
* The outputs of the `tanh` and `sigmoid` activations are combined using `elem_mult` (blue).
* The output of the `elem_mult` is then passed through a `tanh` activation (brown) to produce *h<sub>t</sub>*.
* Input *c<sub>t-1</sub>* is passed through an `identity` function (yellow) and then combined with the output of another `elem_mult` (blue) via an `add` operation (orange).
* The output of this `add` operation is passed through an `elem_mult` function (blue) to produce *c<sub>t</sub>*.
**Cell 3 (Bottom)**
* Input *x<sub>t</sub>* is fed into four `add` operations.
* Input *h<sub>t-1</sub>* is fed into three `max` operations (red).
* Input *c<sub>t-1</sub>* is fed into three `max` operations (red).
* The outputs of these `add` operations are then passed through `tanh`, `identity`, `relu`, and `tanh` activations (brown, yellow, pink, brown).
* The outputs of the `tanh` and `sigmoid` activations are combined using `elem_mult` (blue).
* The output of the `elem_mult` is then passed through a `tanh` activation (brown) to produce *h<sub>t</sub>*.
* Input *c<sub>t-1</sub>* is passed through an `identity` function (yellow) and then combined with the output of another `elem_mult` (blue) via an `add` operation (orange).
* The output of this `add` operation is passed through an `identity` function (yellow) to produce *c<sub>t</sub>*.
### Key Observations
* Each cell processes inputs *x<sub>t</sub>*, *h<sub>t-1</sub>*, and *c<sub>t-1</sub>* differently, using various combinations of activation functions and operations.
* The `elem_mult` operation is a key component in combining the outputs of different activation functions.
* The `add` operation is used to combine the inputs with the outputs of previous operations.
* The `identity` function is used to pass the cell state *c<sub>t-1</sub>* to the next time step.
* The variations in the cells likely represent different architectures or design choices for RNNs.
### Interpretation
The diagrams illustrate the computational flow within three different RNN cell architectures. These cells likely represent variations of LSTM or GRU cells, which are designed to address the vanishing gradient problem in traditional RNNs. The different combinations of activation functions, element-wise multiplications, and additions allow each cell to learn different patterns in the input data. The presence of cell state *c<sub>t</sub>* allows the network to store and propagate information across time steps, enabling it to capture long-range dependencies in sequential data. The variations in the cells likely reflect different trade-offs between computational complexity and performance on specific tasks.