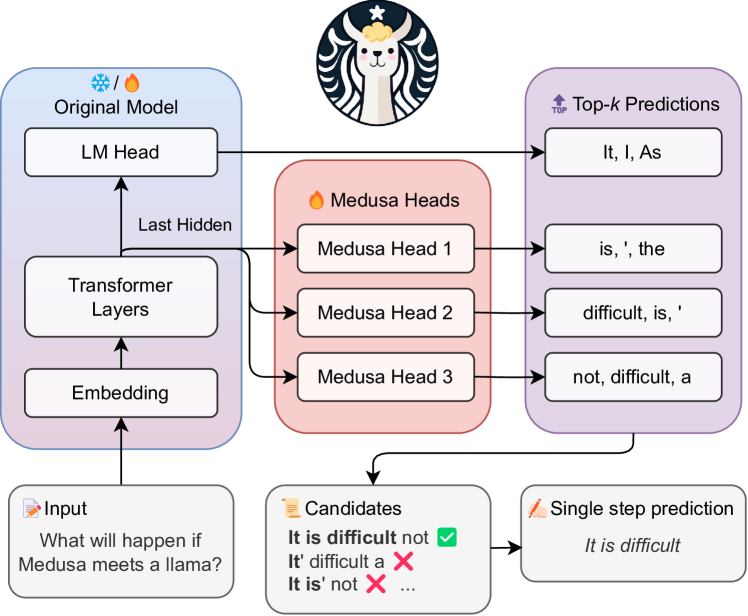
# Technical Diagram Analysis: Medusa Architecture for LLM Acceleration
This document provides a detailed technical extraction of the provided architectural diagram, which illustrates the "Medusa" method for accelerating Large Language Model (LLM) inference.
## 1. Component Isolation
The diagram is organized into five primary functional regions:
1. **Header:** Branding/Logo.
2. **Original Model (Blue Block):** The base transformer architecture.
3. **Medusa Heads (Red Block):** The parallel prediction heads.
4. **Top-k Predictions (Purple Block):** The output tokens from each head.
5. **Footer/Processing Logic:** Input, candidate verification, and final prediction.
---
## 2. Detailed Component Extraction
### Header
* **Logo:** A circular emblem featuring a stylized llama with a star above its head, framed by wavy hair reminiscent of the Starbucks logo (a play on "Medusa" and "Llama").
### Original Model (Blue Region - Left)
This region represents the standard frozen or base model.
* **Labels:** ❄️ / 🔥 Original Model
* **Internal Flow:**
* **Embedding:** The entry point for input data.
* **Transformer Layers:** The core processing block.
* **LM Head:** The standard Language Modeling head that predicts the next token.
* **Data Path:** An arrow labeled **"Last Hidden"** originates from the output of the Transformer Layers and branches to both the LM Head and the Medusa Heads.
### Medusa Heads (Red Region - Center)
This region represents the additional heads added to the model.
* **Label:** 🔥 Medusa Heads
* **Components:**
* **Medusa Head 1**
* **Medusa Head 2**
* **Medusa Head 3**
* **Input:** All three heads receive the "Last Hidden" state from the Transformer Layers in parallel.
### Top-k Predictions (Purple Region - Right)
This region displays the candidate tokens generated by each head.
* **Label:** 🔝 Top-$k$ Predictions
* **Data Mapping:**
| Source | Predictions |
| :--- | :--- |
| **LM Head** | "It, I, As" |
| **Medusa Head 1** | "is, ', the" |
| **Medusa Head 2** | "difficult, is, '" |
| **Medusa Head 3** | "not, difficult, a" |
### Footer / Logic Flow (Bottom)
* **Input Block:**
* **Label:** 📝 Input
* **Text:** "What will happen if Medusa meets a Llama?"
* **Candidates Block:**
* **Label:** 📜 Candidates
* **Content:**
* **It is difficult** not ✅ (Indicated as the correct/accepted sequence)
* **It'** difficult a ❌
* **It is'** not ❌
* ... (Ellipsis indicating further candidates)
* **Single Step Prediction Block:**
* **Label:** ✍️ Single step prediction
* **Text:** *It is difficult*
---
## 3. Process Flow and Logic
1. **Input Processing:** The text "What will happen if Medusa meets a Llama?" is fed into the **Embedding** layer and processed through **Transformer Layers**.
2. **Parallel Generation:** Instead of generating one token, the **Last Hidden** state is sent to the **LM Head** and three **Medusa Heads** simultaneously.
3. **Token Proposal:**
* The LM Head predicts the immediate next token (e.g., "It").
* Medusa Head 1 predicts the token after that (e.g., "is").
* Medusa Head 2 predicts the third token (e.g., "difficult").
* Medusa Head 3 predicts the fourth token (e.g., "not").
4. **Candidate Assembly:** The system combines the top-$k$ results from all heads to create multiple potential sentence continuations (Candidates).
5. **Verification:** The candidates are checked for linguistic validity.
* The sequence "**It is difficult**" is validated.
* Incorrect combinations like "**It' difficult**" are rejected.
6. **Output:** In a **Single step prediction**, the model successfully outputs multiple tokens (*It is difficult*) at once, rather than generating them one by one, thereby increasing inference speed.
## 4. Symbol Legend
* ❄️: Likely represents "Frozen" parameters (Original Model).
* 🔥: Likely represents "Trainable" parameters (Medusa Heads).
* ✅: Validated/Accepted candidate.
* ❌: Rejected candidate.