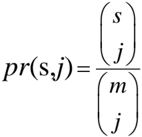## Formula: Probability Calculation
### Overview
The image displays a mathematical formula for calculating probability, denoted as \( pr(s,j) \). The formula is structured as a fraction with a numerator and denominator, both represented as vertical arrays.
### Components/Axes
- **Formula Structure**:
- **Numerator**: A vertical array labeled with \( s \) (top) and \( j \) (bottom).
- **Denominator**: A vertical array labeled with \( m \) (top) and \( j \) (bottom).
- **Notation**:
- \( pr(s,j) \): Probability of event \( s \) occurring in context \( j \).
- \( s_j \): Likely represents the count of successes or specific instances in group \( j \).
- \( m_j \): Likely represents the total number of trials or instances in group \( j \).
### Detailed Analysis
- The formula \( pr(s,j) = \frac{s_j}{m_j} \) calculates probability as the ratio of successes (\( s_j \)) to total trials (\( m_j \)) in a specific context (\( j \)).
- The vertical arrays suggest hierarchical or grouped data, where \( j \) acts as a subscript/index for both numerator and denominator.
### Key Observations
- The formula assumes \( m_j > 0 \) to avoid division by zero.
- The use of \( j \) as a subscript implies the formula applies to multiple groups or categories.
- No numerical values or specific data points are provided in the image.
### Interpretation
This formula represents a foundational probability calculation, likely used in statistical or experimental contexts. The subscript \( j \) indicates the formula is generalized for multiple scenarios or datasets. The absence of numerical values suggests it is a template for computation rather than a specific dataset. The structure emphasizes the relationship between successes, trials, and context, critical for understanding distributions or success rates in grouped data.