TECHNICAL ASSET FINGERPRINT
c958cd441317879bc828d192
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
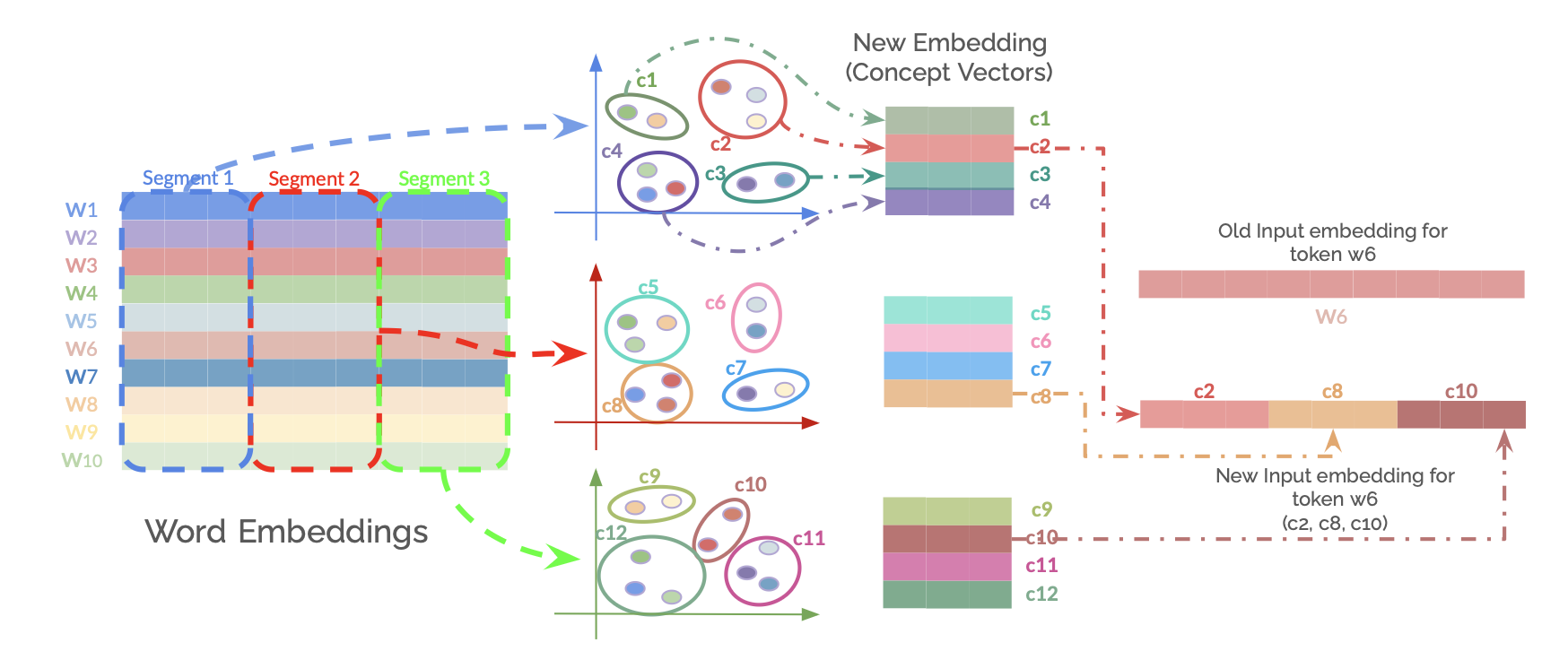
## Diagram: Concept Vector Decomposition and Recombination for Word Embeddings
### Overview
This technical diagram illustrates a process for transforming word embeddings into a set of "concept vectors" and then using a subset of those concepts to construct a new, modified input embedding for a specific token. The flow moves from left to right, showing decomposition, clustering, and recombination.
### Components/Axes
The diagram is segmented into three primary regions:
1. **Left Region: Word Embeddings Matrix**
* A grid labeled "Word Embeddings".
* **Rows:** Labeled `W1` through `W10` (representing 10 distinct word tokens).
* **Columns:** Grouped into three vertical segments, indicated by dashed colored boxes and labels at the top:
* `Segment 1` (Blue dashed box)
* `Segment 2` (Red dashed box)
* `Segment 3` (Green dashed box)
* Each cell in the matrix is filled with a unique color, representing the embedding values for a given word token across different dimensions or features.
2. **Middle Region: Concept Vector Clusters**
* Three separate 2D coordinate systems (plots), each with unlabeled X and Y axes (implied to represent a conceptual or latent space).
* Each plot contains clusters of colored points, representing "concepts" derived from a segment of the word embeddings.
* **Top Plot (from Segment 1):** Contains clusters labeled `c1` (green), `c2` (red), `c3` (teal), `c4` (purple).
* **Middle Plot (from Segment 2):** Contains clusters labeled `c5` (light green), `c6` (pink), `c7` (blue), `c8` (orange).
* **Bottom Plot (from Segment 3):** Contains clusters labeled `c9` (olive), `c10` (brown), `c11` (magenta), `c12` (dark green).
* To the right of these plots is a legend-like structure titled **"New Embedding (Concept Vectors)"**. It shows stacked colored bars corresponding to the concept labels:
* `c1` (green bar), `c2` (red bar), `c3` (teal bar), `c4` (purple bar)
* `c5` (light green bar), `c6` (pink bar), `c7` (blue bar), `c8` (orange bar)
* `c9` (olive bar), `c10` (brown bar), `c11` (magenta bar), `c12` (dark green bar)
3. **Right Region: Embedding Recombination**
* **Top Element:** A solid, light red horizontal bar labeled **"Old Input embedding for token w6"**. Below it, the label `W6` is written in a matching light red color.
* **Bottom Element:** A new, multi-colored horizontal bar labeled **"New Input embedding for token w6 (c2, c8, c10)"**. This bar is segmented into three colored sections:
* Left section: Red (matching `c2`).
* Middle section: Orange (matching `c8`).
* Right section: Brown (matching `c10`).
* **Flow Arrows:**
* A dashed blue arrow originates from `Segment 1` of the Word Embeddings matrix and points to the top Concept Vector plot.
* A dashed red arrow originates from `Segment 2` and points to the middle Concept Vector plot.
* A dashed green arrow originates from `Segment 3` and points to the bottom Concept Vector plot.
* A dashed red arrow originates from the `c2` bar in the "New Embedding" legend and points to the red section of the "New Input embedding".
* A dashed orange arrow originates from the `c8` bar and points to the orange section of the "New Input embedding".
* A dashed brown arrow originates from the `c10` bar and points to the brown section of the "New Input embedding".
### Detailed Analysis
The process depicted is a multi-stage transformation:
1. **Segmentation & Decomposition:** The original word embedding matrix (W1-W10) is split into three distinct segments (1, 2, 3). Each segment is processed independently.
2. **Concept Extraction:** Each segment's data is projected into a latent space, forming clusters of points. Each cluster is assigned a unique concept identifier (`c1` through `c12`). The color of each cluster in the plots corresponds to the color of its label bar in the "New Embedding (Concept Vectors)" legend.
3. **Concept Selection:** For the specific token `w6`, three concepts are selected: `c2` (from Segment 1), `c8` (from Segment 2), and `c10` (from Segment 3).
4. **Embedding Construction:** A new input embedding for token `w6` is constructed by concatenating the vectors representing the selected concepts (`c2`, `c8`, `c10`). This new embedding is visually distinct from the "Old Input embedding" for the same token, which is shown as a uniform block.
### Key Observations
* **Color Consistency:** The diagram maintains strict color consistency. The color of a concept cluster (e.g., `c2` red cluster) matches its bar in the legend, which in turn matches the segment of the final "New Input embedding" it contributes to.
* **Spatial Flow:** The layout clearly guides the viewer from raw data (left), through an analytical/transformative process (middle), to a synthesized output (right).
* **Selective Recombination:** The new embedding is not a simple average or combination of all concepts. It is a deliberate, sparse selection of specific concepts (`c2`, `c8`, `c10`) from different original segments, suggesting a targeted modification of the token's representation.
* **Dimensionality Implication:** The transition from a multi-column matrix to 2D concept clusters and then to a 1D concatenated vector implies a process of dimensionality reduction followed by feature selection and re-projection.
### Interpretation
This diagram likely illustrates a technique for **interpretable or controllable text representation learning**. The core idea is to decompose a word's embedding (which is often a dense, opaque vector) into a set of human- or model-interpretable "concepts."
* **What it suggests:** The model can disentangle different semantic or syntactic facets of a word (represented by segments and then concepts). By selecting specific concepts (`c2`, `c8`, `c10`), one can construct a new embedding for the same word (`w6`) that emphasizes certain desired properties while suppressing others. For example, `c2` might represent "grammatical number," `c8` might represent "sentiment," and `c10` might represent "topic domain."
* **How elements relate:** The segments in the original embedding are the source material. The concept clusters are the extracted, interpretable features. The final embedding is the application of those features for a specific purpose—perhaps to debias the word representation, adapt it to a specific context, or analyze its semantic components.
* **Notable implication:** The "Old" vs. "New" embedding for `w6` highlights that a word's representation is not fixed. It can be dynamically recomposed based on which underlying concepts are activated or selected, offering a powerful mechanism for fine-grained control in NLP models. The process moves from a holistic representation to an analytical decomposition and finally to a synthetic, purpose-built representation.
DECODING INTELLIGENCE...