TECHNICAL ASSET FINGERPRINT
c971a1cf5c2b7f840b21b5c2
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
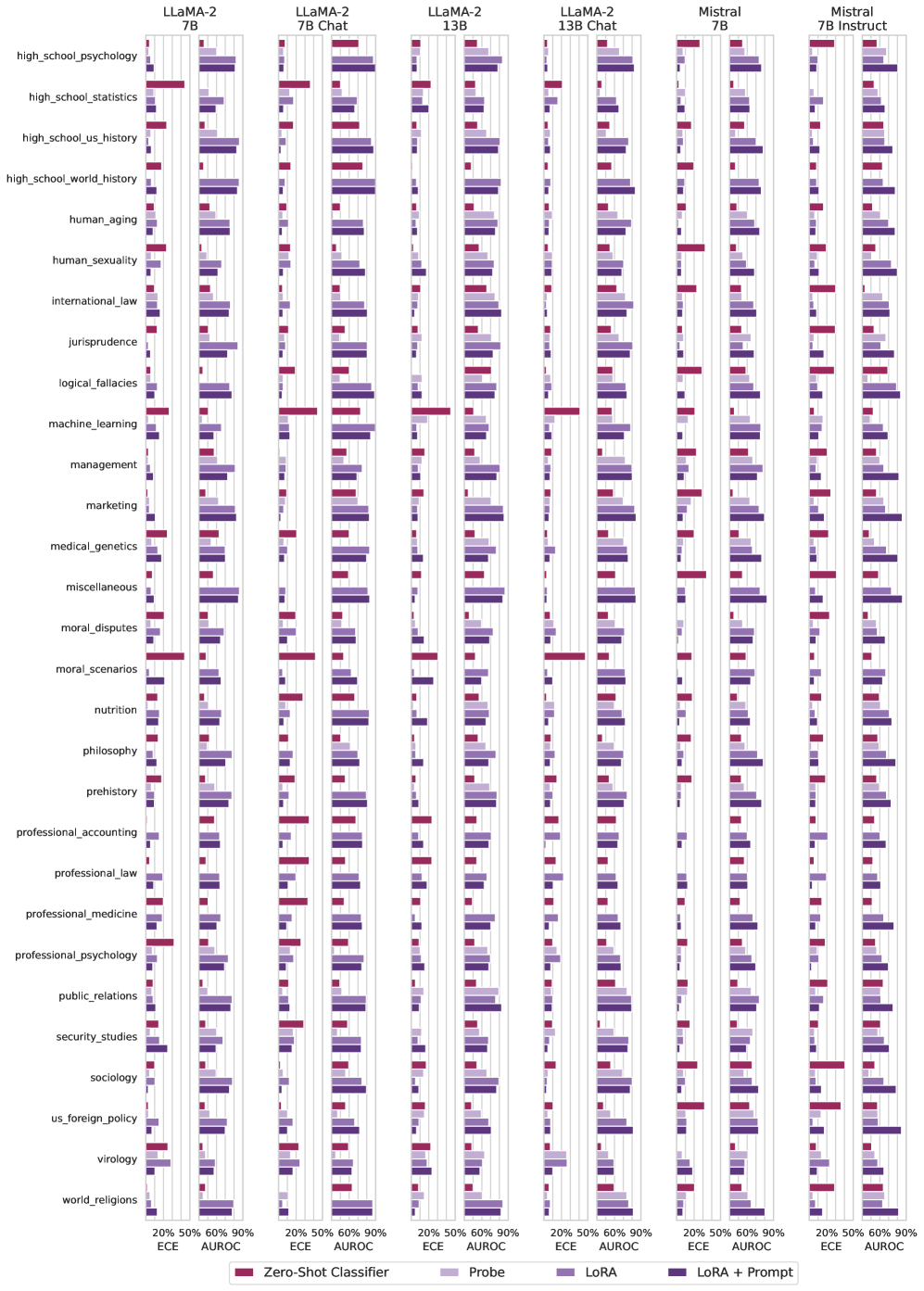
## Grouped Bar Chart: Language Model Performance Across Academic Subjects (ECE & AUROC)
### Overview
This image is a complex, multi-panel grouped bar chart comparing the performance of six different Large Language Models (LLMs) across 30 academic subjects. Performance is measured using two metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic Curve (AUROC). For each model and subject, four different methods are evaluated: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt.
### Components/Axes
* **Chart Type:** Multi-panel grouped horizontal bar chart.
* **Panels (Columns):** Six distinct panels, each representing a different LLM. From left to right:
1. LLaMA-2 7B
2. LLaMA-2 7B Chat
3. LLaMA-2 13B
4. LLaMA-2 13B Chat
5. Mistral 7B
6. Mistral 7B Instruct
* **Y-Axis (Rows):** Lists 30 academic subjects. From top to bottom:
`high_school_psychology`, `high_school_statistics`, `high_school_us_history`, `high_school_world_history`, `human_aging`, `human_sexuality`, `international_law`, `jurisprudence`, `logical_fallacies`, `machine_learning`, `management`, `marketing`, `medical_genetics`, `miscellaneous`, `moral_disputes`, `moral_scenarios`, `nutrition`, `philosophy`, `prehistory`, `professional_accounting`, `professional_law`, `professional_medicine`, `professional_psychology`, `public_relations`, `security_studies`, `sociology`, `us_foreign_policy`, `virology`, `world_religions`.
* **X-Axis (Metrics):** Each panel has two sub-columns at the bottom, labeled:
* **ECE** (Expected Calibration Error): Scale from 0% to approximately 20%. Lower values are better.
* **AUROC** (Area Under the ROC Curve): Scale from 50% to 90%. Higher values are better.
* **Legend (Bottom Center):** Four colored bars define the methods:
* **Maroon/Dark Red:** Zero-Shot Classifier
* **Light Purple/Lavender:** Probe
* **Medium Purple:** LoRA
* **Dark Purple/Indigo:** LoRA + Prompt
* **Spatial Layout:** The legend is positioned at the bottom center of the entire figure. Each of the six model panels is arranged vertically, with subjects listed on the far left. Within each panel, for every subject, four horizontal bars are grouped together, corresponding to the four methods in the legend.
### Detailed Analysis
**General Trends Across All Models:**
1. **Metric Comparison:** For nearly all subjects and models, the AUROC bars (right sub-column) are significantly longer than the ECE bars (left sub-column), indicating that models generally achieve moderate to good discriminative ability (AUROC > 50%) while maintaining relatively low calibration error (ECE < ~15%).
2. **Method Performance Hierarchy:** A consistent pattern is visible across most subjects and models:
* **Zero-Shot Classifier (Maroon):** Typically shows the shortest bars for AUROC and often the longest bars for ECE, indicating the poorest performance.
* **Probe (Light Purple):** Shows a clear improvement over Zero-Shot, with longer AUROC bars and shorter ECE bars.
* **LoRA (Medium Purple) & LoRA + Prompt (Dark Purple):** These two methods consistently perform the best. Their bars are often very close in length, with LoRA + Prompt showing a slight, consistent edge in AUROC (longer bar) and a slight edge in ECE (shorter bar) over LoRA alone in many cases.
**Model-Specific Observations:**
* **LLaMA-2 7B vs. 7B Chat:** The Chat variant generally shows improved AUROC scores (longer bars) across many subjects compared to the base 7B model, particularly for the fine-tuned methods (Probe, LoRA).
* **LLaMA-2 13B vs. 13B Chat:** Similar to the 7B pair, the 13B Chat model often outperforms the base 13B model in AUROC, though the difference appears less dramatic than in the 7B case.
* **Mistral 7B vs. 7B Instruct:** The Instruct variant shows a very strong performance boost over the base Mistral 7B. The AUROC bars for LoRA/LoRA+Prompt in the Instruct model are frequently among the longest in the entire chart, often exceeding 80%.
* **Scale (7B vs. 13B):** Comparing LLaMA-2 7B to 13B, the larger 13B model shows a modest but visible improvement in AUROC for most methods and subjects.
**Subject-Specific Highlights (Approximate Values):**
* **High ECE (Poor Calibration):** The `machine_learning` subject often shows relatively high ECE values (bars extending further left) across models, especially for the Zero-Shot method. `moral_scenarios` also shows notable ECE.
* **High AUROC (Strong Discrimination):** Subjects like `high_school_psychology`, `professional_psychology`, and `sociology` frequently show very high AUROC scores (>80%) for the best-performing methods (LoRA + Prompt) across multiple models.
* **Challenging Subjects:** Subjects like `professional_law`, `international_law`, and `jurisprudence` tend to have shorter AUROC bars overall, suggesting they are more difficult for the models to classify correctly.
### Key Observations
1. **Fine-Tuning is Crucial:** The most striking pattern is the substantial performance gap between the Zero-Shot Classifier and all other methods (Probe, LoRA, LoRA+Prompt). This demonstrates that some form of adaptation or fine-tuning is essential for strong performance on these academic tasks.
2. **Instruction Tuning Matters:** The "Chat" and "Instruct" variants of models consistently outperform their base counterparts, highlighting the value of instruction-following training for these types of knowledge-based QA tasks.
3. **LoRA + Prompt is the Top Performer:** The dark purple bars (LoRA + Prompt) are almost universally the longest for AUROC and the shortest for ECE, indicating this combined approach yields the best calibrated and most accurate models.
4. **Performance Variability:** There is significant variability in model performance across different academic subjects, indicating that model knowledge and reasoning ability are not uniform across domains.
### Interpretation
This chart provides a comprehensive benchmark of LLM capabilities across a wide spectrum of academic knowledge. The data suggests several key insights:
1. **The Necessity of Adaptation:** The poor performance of the Zero-Shot Classifier underscores that simply using a pre-trained LLM's internal knowledge is insufficient for high-accuracy, well-calibrated classification on specialized academic topics. Parameter-efficient fine-tuning methods like LoRA are highly effective.
2. **Synergy of Methods:** The consistent, albeit sometimes small, superiority of "LoRA + Prompt" over "LoRA" alone suggests that combining parameter-efficient fine-tuning with optimized prompting creates a synergistic effect, leading to better model performance than either technique in isolation.
3. **Model Architecture and Training Impact:** The comparison between base and chat/instruct models, and between 7B and 13B parameter models, illustrates that both the training objective (instruction tuning) and model scale contribute positively to performance. The Mistral 7B Instruct model's strong showing suggests its training regimen is particularly effective for this evaluation setup.
4. **Domain-Specific Challenges:** The variation in performance across subjects (e.g., law vs. psychology) implies that the underlying training data of these models may be imbalanced, or that some domains require more complex reasoning that is harder for the models to capture. This has implications for using LLMs as general-purpose knowledge engines.
**In summary, the chart is a detailed map of LLM performance, revealing that while base models have foundational knowledge, achieving high accuracy and reliability on academic tasks requires targeted fine-tuning and prompting strategies, with the combination of LoRA and prompt engineering emerging as the most robust approach among those tested.**
DECODING INTELLIGENCE...