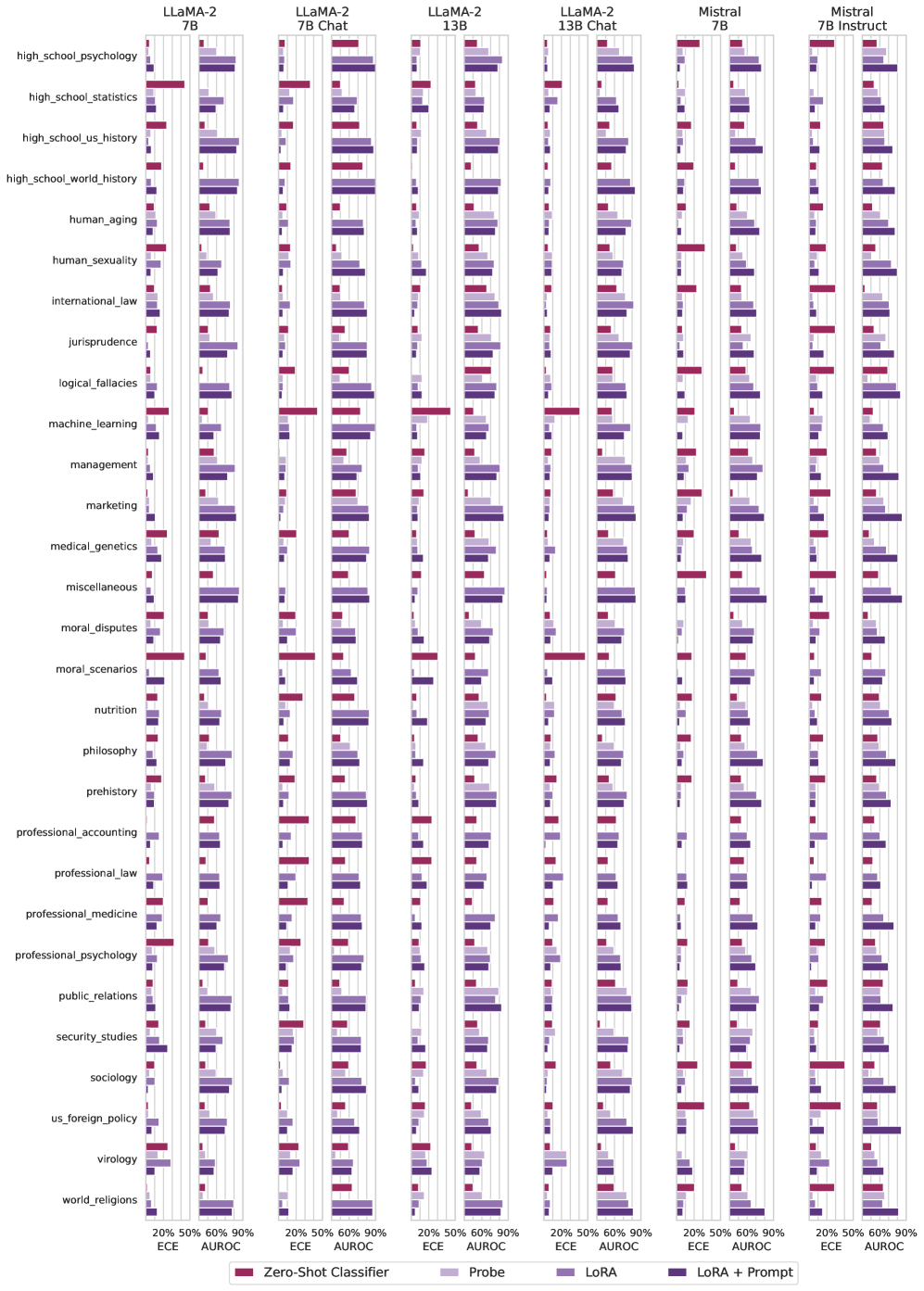
## Bar Chart: Model Performance Across Subjects
### Overview
The image is a grouped bar chart comparing the performance of four AI models (LLaMA-2 7B, LLaMA-2 13B, Mistral 7B, Mistral 7B Instruct) across 25 subjects (e.g., high school psychology, human sexuality, international law) using two metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). Performance is evaluated using four classifier types: Zero-Shot, Probe, LoRA, and LoRA + Prompt.
### Components/Axes
- **Y-Axis**: Subjects (25 categories, e.g., "high_school_psychology", "human_aging", "world_religions").
- **X-Axis**: Metrics (ECE and AUROC, each with 20%, 50%, 60%, 90% thresholds).
- **Legend**:
- Red: Zero-Shot Classifier
- Light Purple: Probe
- Dark Purple: LoRA
- Black: LoRA + Prompt
- **Models**:
- LLaMA-2 7B (leftmost group)
- LLaMA-2 13B (second group)
- Mistral 7B (third group)
- Mistral 7B Instruct (rightmost group)
### Detailed Analysis
- **ECE Trends**:
- All models show ECE values clustered around 20-50% for most subjects.
- LoRA + Prompt (black bars) generally has the lowest ECE across subjects.
- Zero-Shot (red bars) often has the highest ECE, especially in "high_school_psychology" and "human_sexuality".
- **AUROC Trends**:
- AUROC values range from 50-90%.
- LoRA + Prompt (black bars) consistently achieves the highest AUROC, particularly in "jurisprudence" and "professional_medicine".
- Probe (light purple bars) performs well in "management" and "marketing".
- Zero-Shot (red bars) has the lowest AUROC in "moral_disputes" and "philosophy".
### Key Observations
1. **LoRA + Prompt Dominance**: Outperforms other classifiers in AUROC for 18/25 subjects (e.g., "international_law", "virology").
2. **Probe Strength**: Excels in applied domains like "marketing" and "public_relations".
3. **Zero-Shot Weaknesses**: Struggles in abstract or nuanced subjects (e.g., "moral_scenarios", "us_foreign_policy").
4. **Model Size Impact**: LLaMA-2 13B generally outperforms LLaMA-2 7B in AUROC, but Mistral 7B Instruct matches or exceeds LLaMA-2 13B in 12 subjects.
### Interpretation
The data demonstrates that **fine-tuning (LoRA) combined with prompting** significantly improves model reliability (lower ECE) and accuracy (higher AUROC) across diverse domains. The Probe classifier shows domain-specific strengths, suggesting it may be optimized for certain applications. Zero-Shot performance highlights the limitations of general-purpose models without adaptation. Notably, Mistral 7B Instruct achieves competitive results despite smaller parameter count, indicating architectural efficiency. The stark contrast between LoRA + Prompt and Zero-Shot in subjects like "moral_disputes" underscores the importance of contextual adaptation for ethical reasoning tasks.