\n
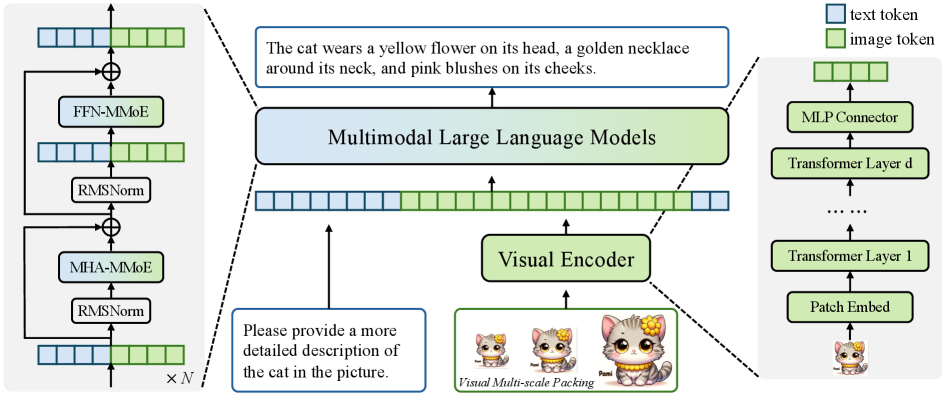
## Diagram: Multimodal Large Language Models Architecture
### Overview
The image depicts a diagram illustrating the architecture of Multimodal Large Language Models. It showcases the interaction between a visual encoder and a transformer-based language model, with a focus on tokenization and processing of both text and image data. The diagram is segmented into two main processing paths: one for text and one for images, converging into a multimodal model.
### Components/Axes
The diagram consists of the following key components:
* **Visual Encoder:** Processes image data. Includes "Visual Multi-scale Packing" and outputs to the Multimodal Large Language Model.
* **Multimodal Large Language Models:** The central processing unit, receiving input from both the visual encoder and text tokens.
* **Text Tokenization:** A series of blocks representing text token processing.
* **Image Tokenization:** A series of blocks representing image token processing.
* **Transformer Layers:** Represented as stacked blocks, with "Transformer Layer d" and "Transformer Layer 1" labeled.
* **MLP Connector:** Connects the transformer layers.
* **Patch Embed:** Initial embedding layer for image data.
* **RMSNorm:** Layer normalization blocks.
* **MHA-MMoE:** Multi-Head Attention with Mixture of Experts.
* **FFN-MMoE:** Feed Forward Network with Mixture of Experts.
* **Legend:** Distinguishes between "text token" (blue) and "image token" (green).
Additionally, there are text annotations:
* "The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."
* "Please provide a more detailed description of the cat in the picture."
* "Visual Multi-scale Packing"
* "x N"
### Detailed Analysis or Content Details
The diagram illustrates a data flow from image input to multimodal processing.
**Image Processing Path (Right to Left):**
1. **Patch Embed:** Image data is initially processed by a "Patch Embed" layer.
2. **Transformer Layer 1:** The embedded image data then passes through "Transformer Layer 1".
3. **Transformer Layer d:** Subsequent layers are represented as "Transformer Layer d" (with ellipses indicating multiple layers).
4. **MLP Connector:** The output of the transformer layers is connected via an "MLP Connector".
5. **Image Token:** The processed image data is represented as "image token" (green) and fed into the Multimodal Large Language Model.
**Text Processing Path (Left Side):**
1. **Text Token:** The input is represented as "text token" (blue).
2. **RMSNorm:** The text tokens pass through an "RMSNorm" layer.
3. **MHA-MMoE:** Then through a "MHA-MMoE" layer.
4. **RMSNorm:** Another "RMSNorm" layer.
5. **FFN-MMoE:** Finally, a "FFN-MMoE" layer.
6. The output of this path is fed into the Multimodal Large Language Model.
**Multimodal Large Language Model (Center):**
* The "Multimodal Large Language Models" block receives input from both the image and text processing paths.
* The connections between the processing paths and the multimodal model are indicated by dashed arrows.
**Annotations:**
* The annotation "The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks." describes the content of the images used in the "Visual Multi-scale Packing" block.
* The annotation "Please provide a more detailed description of the cat in the picture." is a prompt or instruction related to the image content.
* "Visual Multi-scale Packing" indicates a method for processing images at different scales.
* "x N" likely represents a repetition or scaling factor for the text processing path.
### Key Observations
* The diagram emphasizes the parallel processing of text and image data.
* The use of "RMSNorm", "MHA-MMoE", and "FFN-MMoE" suggests a transformer-based architecture with advanced attention mechanisms and mixture of experts.
* The legend clearly distinguishes between text and image tokens, highlighting the multimodal nature of the model.
* The diagram does not provide specific numerical values or performance metrics.
### Interpretation
The diagram illustrates a modern approach to multimodal learning, where language models are augmented with visual processing capabilities. The architecture leverages transformer networks, known for their effectiveness in natural language processing, and extends them to handle image data. The "Visual Encoder" transforms images into a tokenized representation that can be integrated with text tokens, allowing the model to reason about both modalities simultaneously. The use of Mixture of Experts (MoE) in the attention and feed-forward layers suggests an attempt to increase model capacity and improve performance. The annotations highlight the importance of visual context and the need for detailed image descriptions. The overall design suggests a system capable of understanding and generating content based on both textual and visual information. The diagram is conceptual and does not provide quantitative data, but it effectively conveys the key components and data flow of a multimodal large language model.