# Technical Document Extraction: Multimodal System Architecture
## Diagram Overview
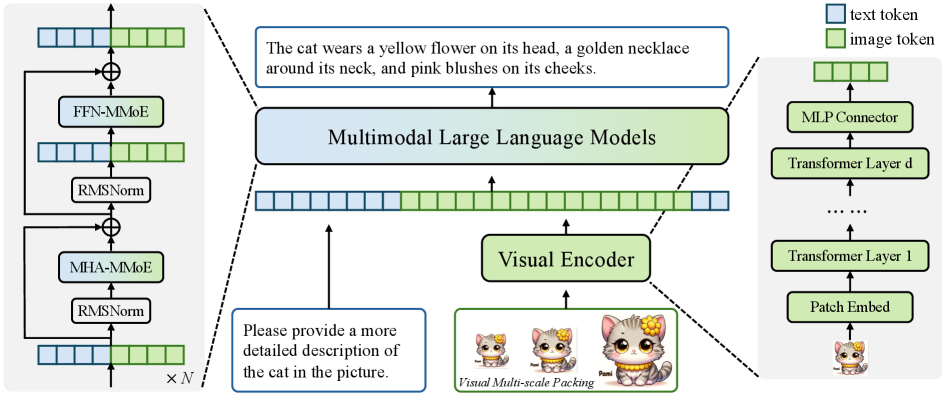
The image depicts a **multimodal system architecture** integrating text and image processing components. The system processes textual descriptions and visual inputs through a series of specialized modules, culminating in a transformer-based output.
---
## Key Components and Flow
### 1. **Input Processing**
- **Textual Input**:
- Example prompt: *"The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."*
- Example request: *"Please provide a more detailed description of the cat in the picture."*
### 2. **Text Tokenization**
- **Text Tokens** (Blue in legend):
- Represented as sequential blocks in the leftmost column.
- Processed through **FFN-MMoE** (Feed-Forward Mixture-of-Experts) and **MHA-MMoE** (Multi-Head Attention Mixture-of-Experts).
- Normalized via **RMSNorm** (Root Mean Square Normalization).
### 3. **Visual Encoder**
- **Image Tokens** (Green in legend):
- Generated from **Patch Embed** (converts images into tokenized patches).
- Processed through **Transformer Layers 1 to d** (stacked transformer blocks).
- Outputs **Visual Multi-scale Packing** (e.g., cartoon-style cat images with varying detail levels).
### 4. **Multimodal Integration**
- **Multimodal Large Language Models**:
- Combines text and image tokens into a unified representation.
- Includes **MLP Connector** (Multi-Layer Perceptron) to bridge modalities.
### 5. **Output Generation**
- Final output is a **Transformer Layer d** output, integrating both modalities.
---
## Legend and Spatial Grounding
- **Legend Location**: Top-right corner.
- **Blue**: Text tokens.
- **Green**: Image tokens.
- **Spatial Confirmation**:
- Text tokens (blue) align with left-side text processing modules.
- Image tokens (green) align with right-side visual encoder components.
---
## Component Descriptions
1. **FFN-MMoE / MHA-MMoE**:
- Specialized modules for text processing using mixture-of-experts architectures.
- Enhances model capacity while maintaining efficiency.
2. **RMSNorm**:
- Normalization layer applied after attention and feed-forward operations.
3. **Visual Encoder**:
- Converts images into tokenized representations via **Patch Embed**.
- Uses **Transformer Layers** for hierarchical feature extraction.
4. **MLP Connector**:
- Integrates text and image embeddings into a unified latent space.
---
## Example Textual Elements
- **Input Prompt**:
- *"The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."*
- **Request for Detail**:
- *"Please provide a more detailed description of the cat in the picture."*
---
## System Flow
1. Text tokens → FFN-MMoE → MHA-MMoE → RMSNorm.
2. Image tokens → Patch Embed → Transformer Layers 1→d → Visual Multi-scale Packing.
3. Combined text/image tokens → Multimodal Large Language Models → MLP Connector → Final Output (Transformer Layer d).
---
## Notes
- No numerical data or trends are present; the diagram focuses on architectural components and workflow.
- All textual elements are in English; no additional languages detected.