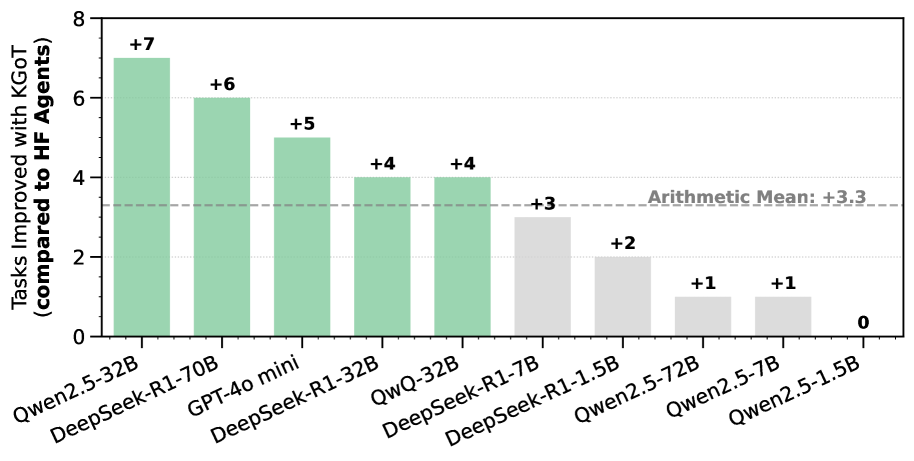
## Bar Chart: Tasks Improved with KGOT Compared to HF Agents
### Overview
The bar chart compares the number of tasks improved by various language models when using KGOT (Knowledge Graph Optimized Training) compared to using HF (Hugging Face) Agents. The y-axis represents the number of tasks improved, and the x-axis lists the different language models. The chart also includes a horizontal line indicating the arithmetic mean of the improvements.
### Components/Axes
* **Y-axis:** "Tasks Improved with KGOT (compared to HF Agents)". Scale ranges from 0 to 8.
* **X-axis:** Categorical axis listing the language models:
* Qwen2.5-32B
* DeepSeek-R1-70B
* GPT-4o mini
* DeepSeek-R1-32B
* QWQ-32B
* DeepSeek-R1-7B
* DeepSeek-R1-1.5B
* Qwen2.5-72B
* Qwen2.5-7B
* Qwen2.5-1.5B
* **Bars:** Represent the number of tasks improved for each language model. The first five bars are light green, and the last five are light gray.
* **Arithmetic Mean Line:** A dashed horizontal line at y = 3.3, labeled "Arithmetic Mean: +3.3".
### Detailed Analysis
The chart displays the following data points:
* **Qwen2.5-32B:** +7 tasks improved (light green)
* **DeepSeek-R1-70B:** +6 tasks improved (light green)
* **GPT-4o mini:** +5 tasks improved (light green)
* **DeepSeek-R1-32B:** +4 tasks improved (light green)
* **QWQ-32B:** +4 tasks improved (light green)
* **DeepSeek-R1-7B:** +3 tasks improved (light gray)
* **DeepSeek-R1-1.5B:** +2 tasks improved (light gray)
* **Qwen2.5-72B:** +1 task improved (light gray)
* **Qwen2.5-7B:** +1 task improved (light gray)
* **Qwen2.5-1.5B:** 0 tasks improved (light gray)
The first five models (Qwen2.5-32B to QWQ-32B) show a higher improvement in tasks compared to the last five models (DeepSeek-R1-7B to Qwen2.5-1.5B).
### Key Observations
* Qwen2.5-32B shows the highest improvement with +7 tasks.
* Qwen2.5-1.5B shows no improvement (0 tasks).
* The arithmetic mean improvement is +3.3 tasks.
* There is a clear distinction between the performance of the first five models (light green bars) and the last five models (light gray bars).
### Interpretation
The data suggests that KGOT significantly improves the performance of certain language models compared to using HF Agents. The models Qwen2.5-32B, DeepSeek-R1-70B, GPT-4o mini, DeepSeek-R1-32B, and QWQ-32B benefit the most from KGOT. The models DeepSeek-R1-7B, DeepSeek-R1-1.5B, Qwen2.5-72B, and Qwen2.5-7B show a moderate improvement, while Qwen2.5-1.5B does not show any improvement. The difference in performance could be attributed to the architecture, size, or training data of the models. The arithmetic mean provides a general benchmark for the average improvement across all models. The chart highlights the effectiveness of KGOT for specific language models, indicating that KGOT is not universally beneficial and its impact varies depending on the model.