TECHNICAL ASSET FINGERPRINT
cbcd2fd730e39c9993f98999
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
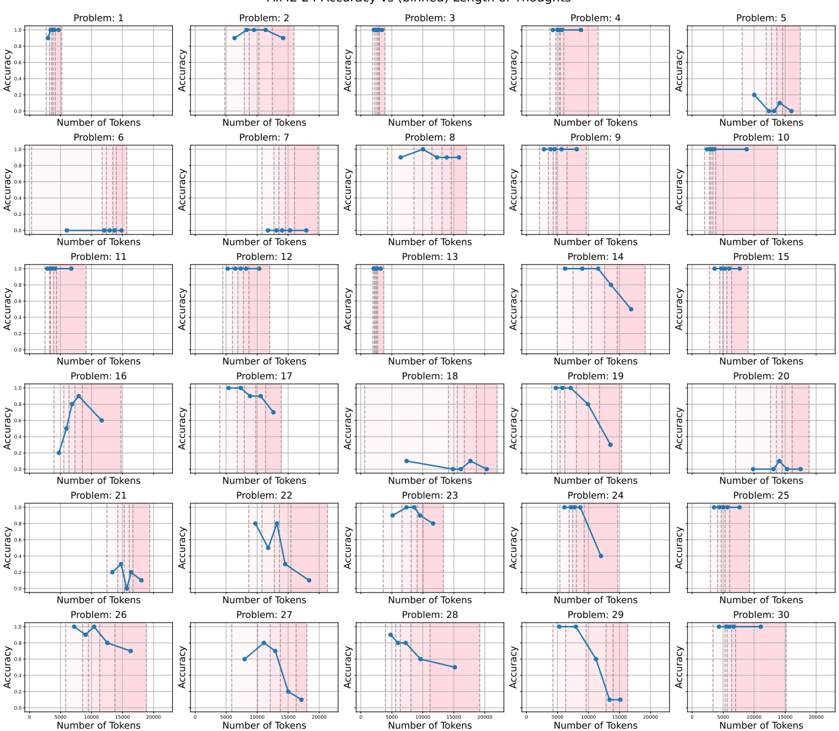
## Chart Type: Accuracy vs. Number of Tokens for 30 Problems
### Overview
The image presents a grid of 30 line charts, each displaying the "Accuracy" versus "Number of Tokens" for a different problem (labeled Problem 1 through Problem 30). The x-axis (Number of Tokens) ranges from approximately 0 to 20000, and the y-axis (Accuracy) ranges from 0 to 1. Each chart shows how accuracy changes as the number of tokens increases. A shaded pink region spans approximately from 5000 to 15000 tokens on the x-axis.
### Components/Axes
* **Title:** "HIML-E Accuracy vs (binned) Length of Thoughts"
* **X-axis:** "Number of Tokens" with a range from 0 to 20000. Major tick marks are present at approximately 5000, 10000, 15000, and 20000.
* **Y-axis:** "Accuracy" with a range from 0 to 1. Major tick marks are present at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Individual Chart Titles:** "Problem: [Number]" where [Number] ranges from 1 to 30.
* **Shaded Region:** A vertical pink shaded region spans from approximately 5000 to 15000 on the x-axis in each chart.
### Detailed Analysis
**Problem 1:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 2:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 3:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 4:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 5:** The accuracy starts at approximately 0.0 and increases slightly to approximately 0.1 as the number of tokens increases.
**Problem 6:** The accuracy starts at approximately 0.0 and remains constant as the number of tokens increases.
**Problem 7:** The accuracy starts at approximately 0.0 and increases slightly to approximately 0.1 as the number of tokens increases.
**Problem 8:** The accuracy starts at approximately 0.0, increases to approximately 0.9, and then remains constant as the number of tokens increases.
**Problem 9:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 10:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 11:** The accuracy starts at approximately 0.0 and remains constant as the number of tokens increases.
**Problem 12:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 13:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 14:** The accuracy starts at approximately 0.8 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 15:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 16:** The accuracy starts at approximately 0.0, increases to approximately 0.9, and then decreases to approximately 0.6 as the number of tokens increases.
**Problem 17:** The accuracy starts at approximately 0.9 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 18:** The accuracy starts at approximately 0.0 and increases slightly to approximately 0.1 as the number of tokens increases.
**Problem 19:** The accuracy starts at approximately 0.8 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 20:** The accuracy starts at approximately 0.0 and increases slightly to approximately 0.1 as the number of tokens increases.
**Problem 21:** The accuracy starts at approximately 0.2 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 22:** The accuracy starts at approximately 0.0, increases to approximately 0.8, and then decreases to approximately 0.0 as the number of tokens increases.
**Problem 23:** The accuracy starts at approximately 0.0, increases to approximately 0.3, and then decreases to approximately 0.0 as the number of tokens increases.
**Problem 24:** The accuracy starts at approximately 0.8 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 25:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
**Problem 26:** The accuracy starts at approximately 0.9 and decreases to approximately 0.7 as the number of tokens increases.
**Problem 27:** The accuracy starts at approximately 0.0, increases to approximately 0.8, and then decreases to approximately 0.0 as the number of tokens increases.
**Problem 28:** The accuracy starts at approximately 0.8 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 29:** The accuracy starts at approximately 0.8 and decreases to approximately 0.0 as the number of tokens increases.
**Problem 30:** The accuracy starts at approximately 0.8 and remains constant as the number of tokens increases.
### Key Observations
* A significant number of problems (1, 2, 3, 4, 9, 10, 12, 13, 15, 25, 30) maintain a high accuracy (around 0.8 or higher) regardless of the number of tokens.
* Several problems (14, 17, 19, 24, 28, 29) show a decrease in accuracy as the number of tokens increases.
* Some problems (5, 6, 7, 11, 18, 20) consistently have low accuracy (around 0.0 to 0.1) regardless of the number of tokens.
* A few problems (8, 16, 22, 23, 27) exhibit a peak in accuracy at a certain number of tokens, followed by a decrease.
* The pink shaded region (5000-15000 tokens) seems to coincide with the region where accuracy tends to decrease in some problems.
### Interpretation
The charts suggest that the relationship between the number of tokens (or "length of thoughts") and accuracy varies significantly across different problems. For some problems, increasing the number of tokens does not affect accuracy, while for others, it leads to a decrease. The pink shaded region might indicate a range of token counts where the model's performance is particularly sensitive or where longer "thoughts" may be detrimental to accuracy for certain problems. The problems with consistently low accuracy may represent cases where the model struggles regardless of the input length. The problems with a peak in accuracy might indicate an optimal "thought" length for those specific tasks. Further investigation would be needed to understand the nature of each problem and why the number of tokens affects accuracy differently.
DECODING INTELLIGENCE...