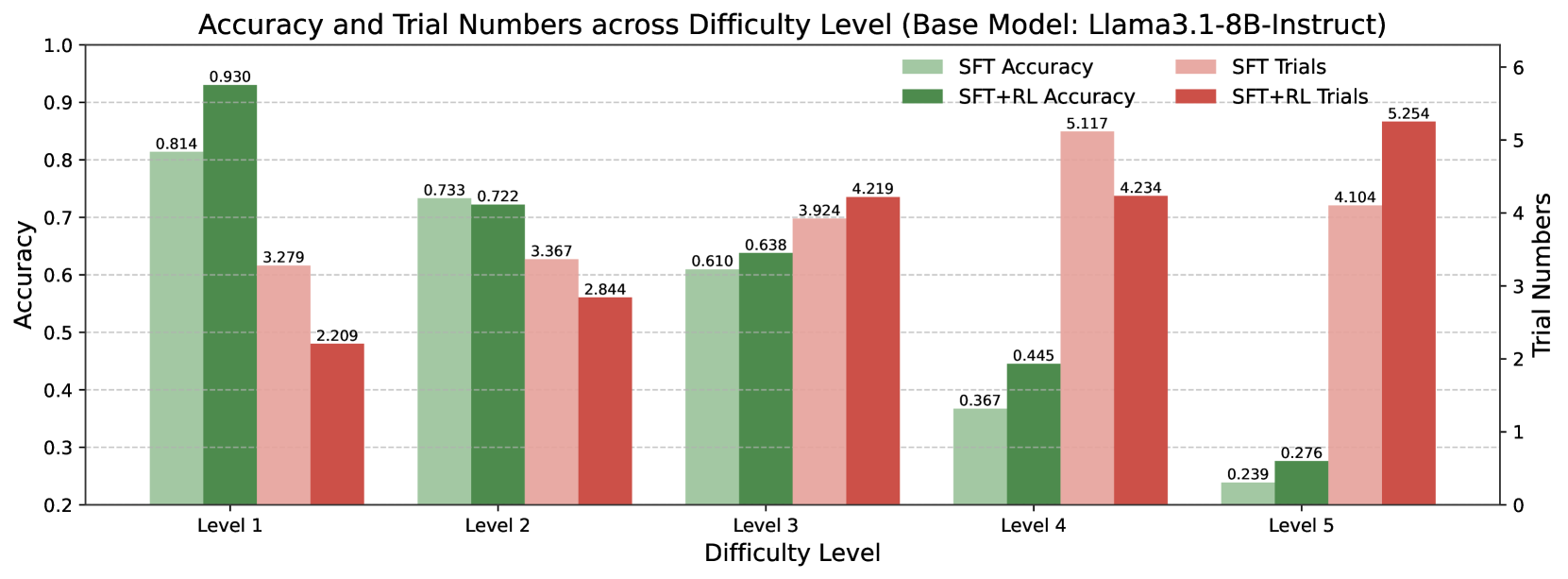
## Bar Chart: Accuracy and Trial Numbers across Difficulty Level (Base Model: Llama3.1-8B-Instruct)
### Overview
The chart compares the accuracy and trial numbers of two model configurations (SFT and SFT+RL) across five difficulty levels (1–5). Accuracy is measured on a 0–1 scale (left y-axis), while trial numbers are counted (right y-axis). The chart uses grouped bars to show performance differences between configurations and difficulty levels.
### Components/Axes
- **X-axis**: Difficulty Level (1–5), labeled "Level 1" to "Level 5"
- **Left Y-axis**: Accuracy (0.2–1.0), labeled "Accuracy"
- **Right Y-axis**: Trial Numbers (0–6), labeled "Trial Numbers"
- **Legend**: Located on the right, with four categories:
- SFT Accuracy (light green)
- SFT+RL Accuracy (dark green)
- SFT Trials (light pink)
- SFT+RL Trials (red)
### Detailed Analysis
#### Accuracy Trends
- **SFT Accuracy** (light green):
- Level 1: 0.814
- Level 2: 0.733
- Level 3: 0.610
- Level 4: 0.367
- Level 5: 0.239
- **SFT+RL Accuracy** (dark green):
- Level 1: 0.930
- Level 2: 0.722
- Level 3: 0.638
- Level 4: 0.445
- Level 5: 0.276
#### Trial Number Trends
- **SFT Trials** (light pink):
- Level 1: 3.279
- Level 2: 3.367
- Level 3: 3.924
- Level 4: 5.117
- Level 5: 4.104
- **SFT+RL Trials** (red):
- Level 1: 2.209
- Level 2: 2.844
- Level 3: 4.219
- Level 4: 4.234
- Level 5: 5.254
### Key Observations
1. **Accuracy Degradation**: Both configurations show declining accuracy with increasing difficulty. SFT+RL maintains higher accuracy than SFT at all levels.
2. **Trial Number Correlation**: Trial numbers generally increase with difficulty, peaking at Level 4 for SFT Trials (5.117) and Level 5 for SFT+RL Trials (5.254).
3. **Performance Gap**: The accuracy gap between SFT and SFT+RL narrows at higher difficulty levels (e.g., 0.575 difference at Level 1 vs. 0.169 at Level 5).
4. **Trial Efficiency**: SFT+RL requires fewer trials than SFT at Levels 1–3 but exceeds SFT trials at Levels 4–5.
### Interpretation
The data suggests that reinforcement learning (RL) improves model robustness across difficulty levels, particularly in maintaining accuracy under challenging conditions. However, the diminishing accuracy gap at higher levels implies RL's benefits may plateau. The trial number patterns indicate that SFT+RL becomes less efficient relative to SFT as difficulty increases, requiring more attempts to achieve comparable results. This could reflect RL's computational overhead or the model's struggle to generalize to extreme difficulty thresholds. The sharp accuracy drop at Level 5 for both configurations highlights a potential limitation in the base model's capacity to handle highly complex tasks.