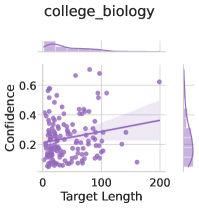
## Scatter Plot with Marginal Distributions: College Biology Confidence vs. Target Length
### Overview
The image is a statistical visualization, specifically a scatter plot with marginal distribution plots (histograms/density plots) on the top and right sides. The chart is titled "college_biology" and explores the relationship between "Target Length" and "Confidence." The overall aesthetic uses a monochromatic purple color scheme against a light grey grid background.
### Components/Axes
* **Title:** "college_biology" (centered at the top).
* **Main Plot Area:** A scatter plot with a fitted regression line and a shaded confidence interval.
* **X-Axis:**
* **Label:** "Target Length"
* **Scale:** Linear, with major tick marks and labels at 0, 100, and 200.
* **Y-Axis:**
* **Label:** "Confidence"
* **Scale:** Linear, with major tick marks and labels at 0.0, 0.2, 0.4, and 0.6.
* **Data Series:**
* **Scatter Points:** Represented by small, semi-transparent purple circles. Each point corresponds to an individual observation.
* **Regression Line:** A solid, darker purple line showing the best-fit linear trend.
* **Confidence Interval:** A lighter purple shaded band surrounding the regression line, indicating the uncertainty of the fit.
* **Marginal Plots:**
* **Top Marginal Plot:** A density plot (or smoothed histogram) showing the distribution of the "Target Length" variable along the x-axis. It is positioned directly above the main plot.
* **Right Marginal Plot:** A density plot showing the distribution of the "Confidence" variable along the y-axis. It is positioned to the right of the main plot.
* **Legend:** No explicit legend is present. The color (purple) is used consistently for all data elements.
### Detailed Analysis
* **Data Distribution & Trend:**
* The scatter points are densely clustered in the lower-left quadrant of the plot, primarily where "Target Length" is between 0 and 100, and "Confidence" is between 0.0 and 0.4.
* The regression line exhibits a clear **positive slope**, rising from left to right. This indicates a positive correlation: as "Target Length" increases, "Confidence" tends to increase.
* The shaded confidence interval around the regression line is narrowest in the region of highest data density (low Target Length) and widens considerably as Target Length increases, indicating greater uncertainty in the trend for larger values due to sparser data.
* **Marginal Distributions:**
* **Target Length (Top):** The distribution is heavily right-skewed. The peak density is at very low values (near 0), with a long tail extending towards 200 and beyond.
* **Confidence (Right):** The distribution is also right-skewed, with the highest density between 0.1 and 0.3, tapering off towards 0.6.
* **Spatial Grounding & Outliers:**
* The majority of data points are concentrated in the region defined by x=[0, 80], y=[0.0, 0.35].
* Several notable outliers exist with high "Target Length" (>150). These points generally have higher "Confidence" values (between ~0.4 and 0.65), which aligns with the positive trend but are sparse.
* The highest "Confidence" value observed is approximately 0.65, associated with a "Target Length" of around 180.
### Key Observations
1. **Positive Correlation:** There is a visible, positive linear relationship between Target Length and Confidence.
2. **Heteroscedasticity:** The variance (spread) of Confidence appears to increase with Target Length. The relationship is tighter for short targets and more variable for long ones.
3. **Skewed Data:** Both variables are not normally distributed; they are right-skewed, meaning most observations involve short target lengths and low-to-moderate confidence levels.
4. **Data Sparsity:** The trend for Target Length > 100 is inferred from a small number of data points, making predictions in that range less reliable.
### Interpretation
The data suggests that in the context of "college_biology," tasks or items with longer "Target Length" (which could refer to the length of a text passage, a sequence, or a problem description) are associated with higher measured "Confidence." This could imply several investigative scenarios:
* **Complexity vs. Assurance:** Longer targets might be more complex, and the confidence metric could reflect a model's or a person's self-assuredness when dealing with more substantial information, even if that assurance isn't necessarily correlated with accuracy.
* **Learning/Exposure Effect:** If "Target Length" correlates with topic familiarity or study time, the trend might indicate that increased engagement leads to higher confidence.
* **Metric Behavior:** The confidence metric itself may be biased or scaled in a way that naturally produces higher values for longer inputs.
The skewed distributions are critical. The strong positive trend is heavily influenced by a cluster of low-length, low-confidence data and a handful of high-length, high-confidence outliers. The widening confidence interval warns against over-interpreting the strength of the relationship for longer targets. A Peircean investigation would question the operational definitions: What exactly is "Target Length"? How is "Confidence" quantified? The anomaly isn't a single point but the sparsity of data in the upper range, which makes the apparent trend more of a hypothesis suggested by outliers than a robustly supported conclusion. The visualization effectively shows both the suggested relationship and the significant uncertainty surrounding it.