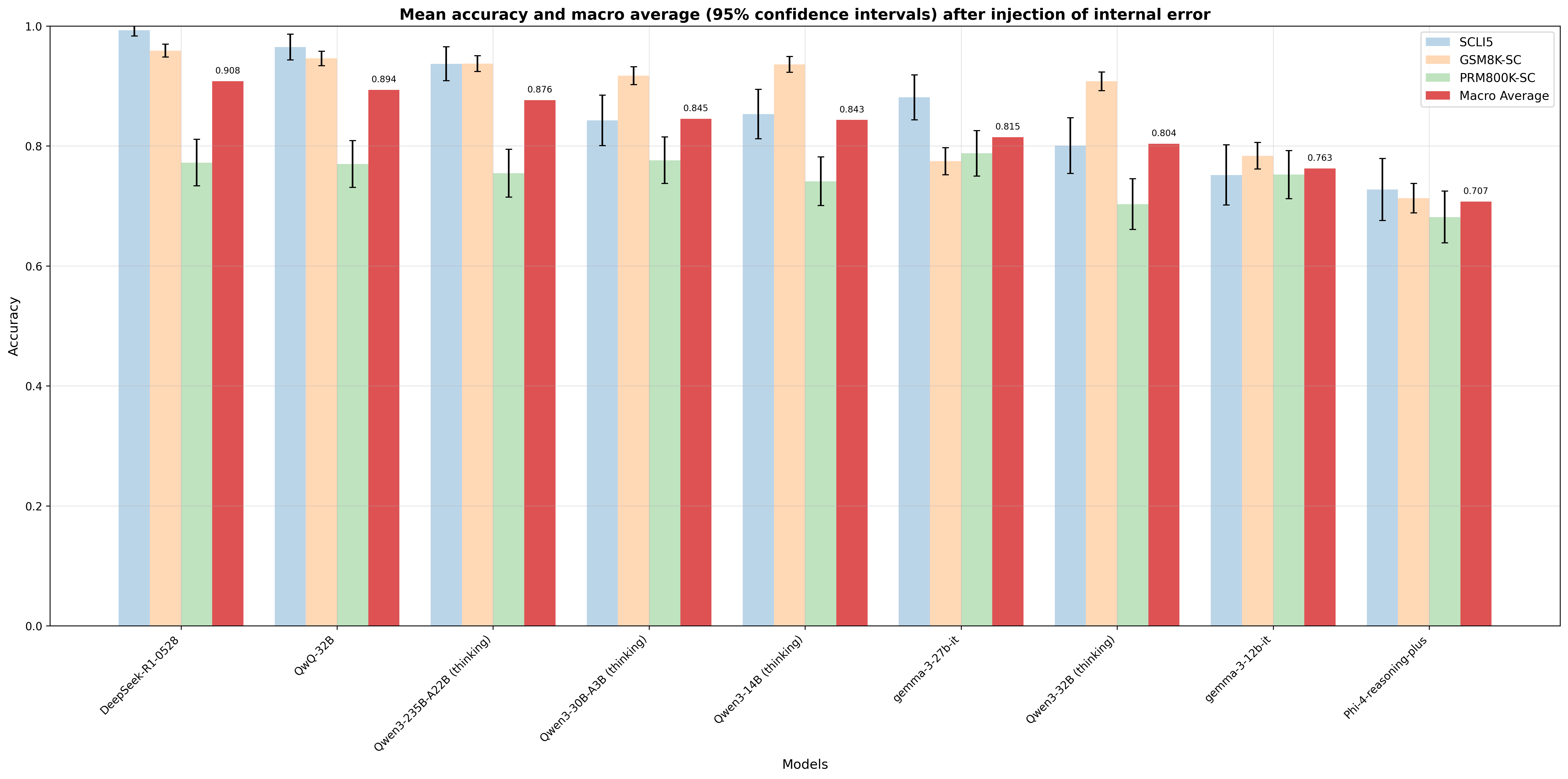
## Bar Chart: Mean Accuracy and Macro Average After Injection of Internal Error
### Overview
The image is a bar chart comparing the mean accuracy and macro average of different models after injecting internal errors. The chart displays the performance of four categories (SCL15, GSM8K-SC, PRM800K-SC, and Macro Average) across various models. Error bars indicate 95% confidence intervals.
### Components/Axes
* **Title:** Mean accuracy and macro average (95% confidence intervals) after injection of internal error
* **X-axis:** Models (DeepSeek-R1-0528, QwQ-32B, Qwen3-235B-A22B (thinking), Qwen3-30B-A3B (thinking), Qwen3-14B (thinking), gemma-3-27b-it, Qwen3-32B (thinking), gemma-3-12b-it, Phi-4-reasoning-plus)
* **Y-axis:** Accuracy (scale from 0.0 to 1.0, incrementing by 0.2)
* **Legend:** Located in the top-right corner.
* SCL15 (light blue)
* GSM8K-SC (light orange)
* PRM800K-SC (light green)
* Macro Average (red)
### Detailed Analysis
**Model Performance Breakdown:**
1. **DeepSeek-R1-0528:**
* SCL15: ~0.98 with a small confidence interval.
* GSM8K-SC: ~0.94 with a small confidence interval.
* PRM800K-SC: ~0.78 with a moderate confidence interval.
* Macro Average: ~0.91.
2. **QwQ-32B:**
* SCL15: ~0.94 with a small confidence interval.
* GSM8K-SC: ~0.93 with a small confidence interval.
* PRM800K-SC: ~0.77 with a moderate confidence interval.
* Macro Average: ~0.91.
3. **Qwen3-235B-A22B (thinking):**
* SCL15: ~0.91 with a small confidence interval.
* GSM8K-SC: ~0.92 with a small confidence interval.
* PRM800K-SC: ~0.77 with a moderate confidence interval.
* Macro Average: ~0.89.
4. **Qwen3-30B-A3B (thinking):**
* SCL15: ~0.85 with a small confidence interval.
* GSM8K-SC: ~0.90 with a small confidence interval.
* PRM800K-SC: ~0.76 with a moderate confidence interval.
* Macro Average: ~0.88.
5. **Qwen3-14B (thinking):**
* SCL15: ~0.85 with a small confidence interval.
* GSM8K-SC: ~0.94 with a small confidence interval.
* PRM800K-SC: ~0.74 with a moderate confidence interval.
* Macro Average: ~0.84.
6. **gemma-3-27b-it:**
* SCL15: ~0.83 with a small confidence interval.
* GSM8K-SC: ~0.82 with a small confidence interval.
* PRM800K-SC: ~0.78 with a moderate confidence interval.
* Macro Average: ~0.82.
7. **Qwen3-32B (thinking):**
* SCL15: ~0.80 with a moderate confidence interval.
* GSM8K-SC: ~0.91 with a small confidence interval.
* PRM800K-SC: ~0.72 with a moderate confidence interval.
* Macro Average: ~0.81.
8. **gemma-3-12b-it:**
* SCL15: ~0.78 with a moderate confidence interval.
* GSM8K-SC: ~0.78 with a small confidence interval.
* PRM800K-SC: ~0.76 with a moderate confidence interval.
* Macro Average: ~0.77.
9. **Phi-4-reasoning-plus:**
* SCL15: ~0.75 with a moderate confidence interval.
* GSM8K-SC: ~0.73 with a small confidence interval.
* PRM800K-SC: ~0.71 with a moderate confidence interval.
* Macro Average: ~0.71.
### Key Observations
* **SCL15 consistently shows high accuracy** across all models, generally above 0.8, except for the last two models (gemma-3-12b-it and Phi-4-reasoning-plus).
* **GSM8K-SC also exhibits high accuracy**, often comparable to or slightly higher than SCL15.
* **PRM800K-SC generally has lower accuracy** compared to the other two, with more variability as indicated by the larger confidence intervals.
* **Macro Average generally falls between PRM800K-SC and the higher-performing SCL15 and GSM8K-SC.**
* The models **DeepSeek-R1-0528 and QwQ-32B** show the highest overall accuracy across all categories.
* The models **gemma-3-12b-it and Phi-4-reasoning-plus** show the lowest overall accuracy across all categories.
### Interpretation
The bar chart illustrates the performance of different models under the stress of injected internal errors. The SCL15 and GSM8K-SC categories consistently outperform PRM800K-SC, suggesting they are more robust to the introduced errors. The Macro Average provides a general performance metric, reflecting the combined performance of all categories. The confidence intervals indicate the reliability of the accuracy measurements; larger intervals suggest greater variability in performance. The models DeepSeek-R1-0528 and QwQ-32B appear to be the most resilient to internal errors, while gemma-3-12b-it and Phi-4-reasoning-plus are the least. This information is valuable for selecting models that maintain high accuracy even when faced with internal inconsistencies or noise.