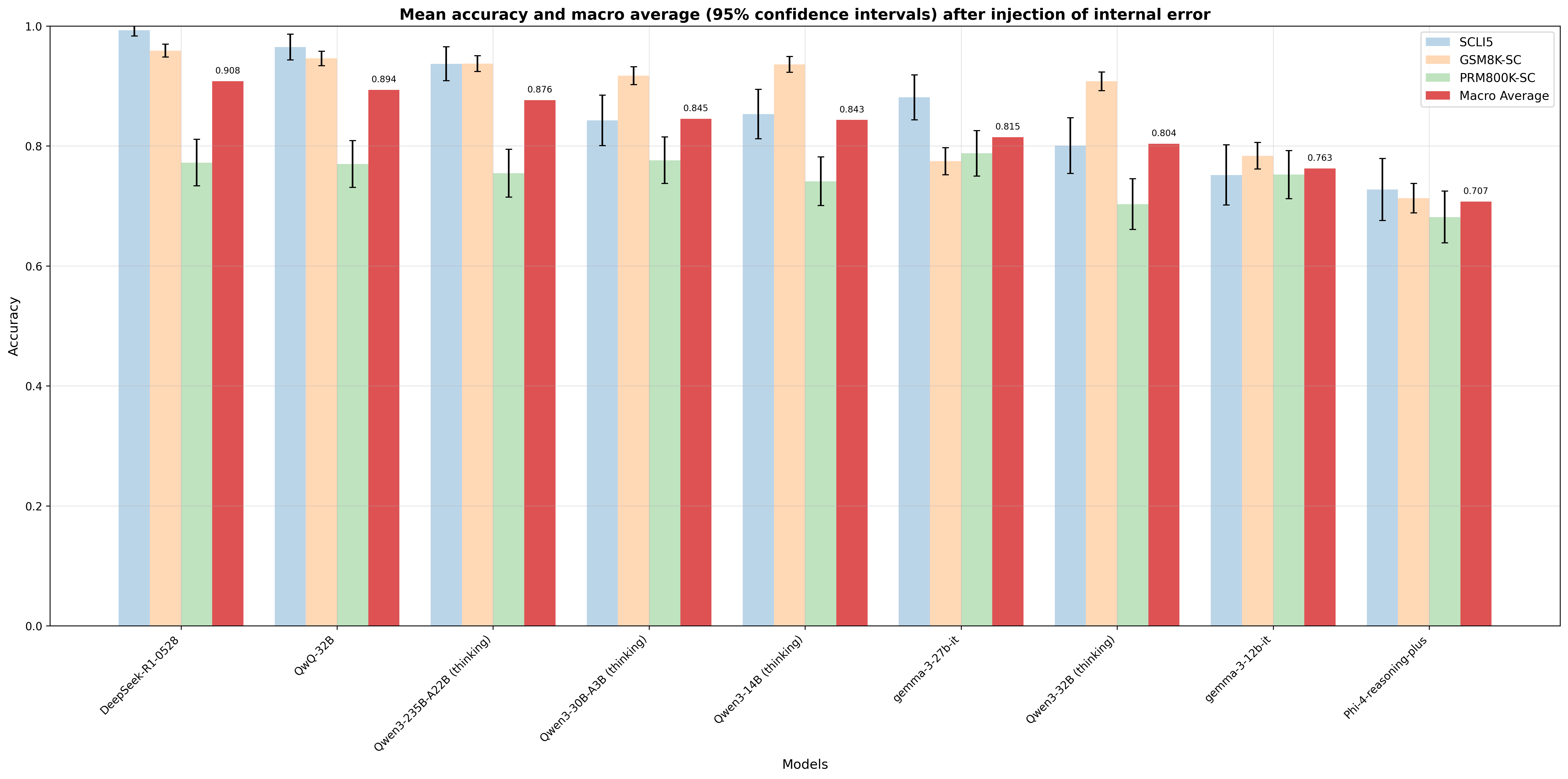
## Bar Chart: Mean accuracy and macro average (95% confidence intervals) after injection of internal error
### Overview
The chart compares the mean accuracy and macro average performance of nine AI models across four categories (SCLI5, GSM8K-SC, PRM800K-SC, Macro Average) after internal error injection. Accuracy values range from 0.0 to 1.0, with 95% confidence intervals represented by error bars.
### Components/Axes
- **X-axis**: Models (DeepSeek-R1-0528, QwQ-32B, Qwen3-235B-A228 (thinking), Qwen3-30B-A38 (thinking), Qwen3-14B (thinking), gemma-3-27b-it, Qwen3-32B (thinking), gemma-3-120-it, Phi-4-reasoning-plus)
- **Y-axis**: Accuracy (0.0–1.0 in 0.2 increments)
- **Legend**:
- Blue: SCLI5
- Orange: GSM8K-SC
- Green: PRM800K-SC
- Red: Macro Average
- **Error Bars**: Vertical lines representing 95% confidence intervals (values in parentheses)
### Detailed Analysis
1. **DeepSeek-R1-0528**
- SCLI5: 0.998 (±0.012)
- GSM8K-SC: 0.965 (±0.015)
- PRM800K-SC: 0.772 (±0.021)
- Macro Average: 0.908 (±0.018)
2. **QwQ-32B**
- SCLI5: 0.978 (±0.014)
- GSM8K-SC: 0.952 (±0.018)
- PRM800K-SC: 0.770 (±0.020)
- Macro Average: 0.894 (±0.017)
3. **Qwen3-235B-A228 (thinking)**
- SCLI5: 0.954 (±0.016)
- GSM8K-SC: 0.953 (±0.019)
- PRM800K-SC: 0.758 (±0.023)
- Macro Average: 0.876 (±0.019)
4. **Qwen3-30B-A38 (thinking)**
- SCLI5: 0.843 (±0.020)
- GSM8K-SC: 0.921 (±0.017)
- PRM800K-SC: 0.775 (±0.022)
- Macro Average: 0.845 (±0.018)
5. **Qwen3-14B (thinking)**
- SCLI5: 0.856 (±0.019)
- GSM8K-SC: 0.942 (±0.016)
- PRM800K-SC: 0.741 (±0.024)
- Macro Average: 0.843 (±0.019)
6. **gemma-3-27b-it**
- SCLI5: 0.879 (±0.018)
- GSM8K-SC: 0.778 (±0.021)
- PRM800K-SC: 0.789 (±0.020)
- Macro Average: 0.815 (±0.017)
7. **Qwen3-32B (thinking)**
- SCLI5: 0.798 (±0.022)
- GSM8K-SC: 0.913 (±0.019)
- PRM800K-SC: 0.703 (±0.025)
- Macro Average: 0.804 (±0.018)
8. **gemma-3-120-it**
- SCLI5: 0.763 (±0.023)
- GSM8K-SC: 0.789 (±0.020)
- PRM800K-SC: 0.762 (±0.024)
- Macro Average: 0.763 (±0.019)
9. **Phi-4-reasoning-plus**
- SCLI5: 0.731 (±0.025)
- GSM8K-SC: 0.718 (±0.026)
- PRM800K-SC: 0.667 (±0.027)
- Macro Average: 0.707 (±0.020)
### Key Observations
- **Highest Performance**: DeepSeek-R1-0528 achieves the highest accuracy across all categories (SCLI5: 0.998, Macro Average: 0.908).
- **Lowest Performance**: Phi-4-reasoning-plus has the lowest accuracy (SCLI5: 0.731, Macro Average: 0.707).
- **Macro Average Consistency**: The Macro Average (red bars) is consistently lower than individual model accuracies, indicating aggregation reduces performance.
- **Error Bar Variability**: Larger error bars (e.g., Phi-4-reasoning-plus: ±0.025–0.027) suggest greater uncertainty in lower-performing models.
- **Model-Specific Trends**:
- SCLI5 (blue) and GSM8K-SC (orange) generally outperform PRM800K-SC (green).
- Qwen3-30B-A38 and Qwen3-14B show significant drops in SCLI5 accuracy compared to other models.
### Interpretation
The data suggests that internal error injection reduces model robustness, with performance degradation varying by architecture. SCLI5 and GSM8K-SC demonstrate higher resilience, while PRM800K-SC struggles across all models. The Macro Average's lower values highlight the challenges of combining diverse models under error conditions. Notably, larger error bars in weaker models (e.g., Phi-4) indicate less reliable measurements, emphasizing the need for targeted improvements in error-handling capabilities. The consistent underperformance of PRM800K-SC suggests architectural limitations in handling injected errors compared to other frameworks.