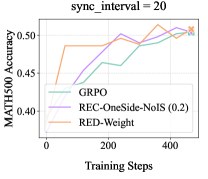
## Line Chart: Algorithm Performance on MATH500 Accuracy (sync_interval = 20)
### Overview
The chart compares the training performance of three algorithms (GRPO, REC-OneSide-NoIS (0.2), and RED-Weight) on the MATH500 accuracy metric over 400 training steps. The y-axis represents accuracy (0.40–0.50), and the x-axis represents training steps (0–400). All lines converge near 0.50 accuracy by the final step, but exhibit distinct trajectories.
### Components/Axes
- **X-axis (Training Steps)**: Labeled "Training Steps," with markers at 0, 200, and 400.
- **Y-axis (MATH500 Accuracy)**: Labeled "MATH500 Accuracy," scaled from 0.40 to 0.50 in 0.05 increments.
- **Legend**: Located in the bottom-right corner, with three entries:
- **GRPO**: Green line.
- **REC-OneSide-NoIS (0.2)**: Purple line.
- **RED-Weight**: Orange line.
- **Title**: "sync_interval = 20" is displayed at the top.
### Detailed Analysis
1. **GRPO (Green Line)**:
- Starts at ~0.40 accuracy at 0 steps.
- Sharp upward trend to ~0.45 accuracy by 200 steps.
- Plateaus at ~0.45 accuracy for the remainder of training (200–400 steps).
2. **REC-OneSide-NoIS (0.2) (Purple Line)**:
- Begins at ~0.40 accuracy at 0 steps.
- Gradual upward trend, reaching ~0.45 accuracy at 200 steps.
- Continues rising to ~0.50 accuracy by 400 steps.
3. **RED-Weight (Orange Line)**:
- Starts at ~0.45 accuracy at 0 steps.
- Dips to ~0.43 accuracy at 200 steps.
- Recovers to ~0.50 accuracy by 400 steps, with minor fluctuations.
### Key Observations
- **GRPO** shows the fastest initial improvement but plateaus earlier than the other algorithms.
- **REC-OneSide-NoIS (0.2)** demonstrates steady, consistent growth, achieving the highest final accuracy (~0.50).
- **RED-Weight** exhibits volatility, with a notable dip at 200 steps before recovering to match the final accuracy of REC-OneSide-NoIS.
- All algorithms converge near 0.50 accuracy by 400 steps, but REC-OneSide-NoIS (0.2) maintains the most stable upward trajectory.
### Interpretation
The chart suggests that **REC-OneSide-NoIS (0.2)** is the most effective algorithm for this task, as it achieves the highest final accuracy with minimal volatility. **GRPO** performs well initially but stagnates, while **RED-Weight**'s fluctuations indicate potential instability in its training process. The "sync_interval = 20" parameter may influence these dynamics, though its exact role is not explained in the chart. The convergence at ~0.50 accuracy implies that all algorithms reach a similar ceiling, but REC-OneSide-NoIS (0.2) does so more efficiently.