\n
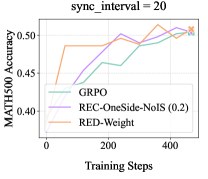
## Line Chart: MATH500 Accuracy vs. Training Steps
### Overview
This line chart depicts the MATH500 accuracy of three different models (GRPO, REC-OneSide-NoIS (0.2), and RED-Weight) as a function of training steps. The chart is labeled with a `sync_interval = 20`.
### Components/Axes
* **X-axis:** Training Steps (ranging from 0 to 500, with markers at 0, 200, and 400)
* **Y-axis:** MATH500 Accuracy (ranging from 0.40 to 0.52, with markers at 0.40, 0.45, 0.50)
* **Legend:** Located in the bottom-left corner.
* GRPO (Light Green Line)
* REC-OneSide-NoIS (0.2) (Purple Line)
* RED-Weight (Orange Line)
### Detailed Analysis
* **GRPO (Light Green Line):** The line starts at approximately 0.43 at 0 training steps. It increases to around 0.48 at 200 training steps, then decreases to approximately 0.47 at 400 training steps, and finally reaches around 0.50 at 500 training steps.
* **REC-OneSide-NoIS (0.2) (Purple Line):** The line begins at approximately 0.40 at 0 training steps. It rises steadily to around 0.47 at 200 training steps, continues to increase to approximately 0.51 at 400 training steps, and then slightly decreases to around 0.50 at 500 training steps.
* **RED-Weight (Orange Line):** The line starts at approximately 0.48 at 0 training steps. It initially decreases to around 0.47 at 100 training steps, then increases to approximately 0.51 at 300 training steps, decreases to around 0.49 at 400 training steps, and finally reaches approximately 0.51 at 500 training steps.
### Key Observations
* All three models show an increasing trend in MATH500 accuracy as training steps increase.
* The REC-OneSide-NoIS (0.2) model appears to achieve the highest accuracy at 400 training steps, reaching approximately 0.51.
* The RED-Weight model starts with the highest accuracy at 0 training steps, but its performance fluctuates more than the other two models.
* The GRPO model has the slowest initial increase in accuracy.
### Interpretation
The chart demonstrates the learning progress of three different models on the MATH500 dataset. The `sync_interval = 20` suggests that model parameters are synchronized every 20 training steps, which could influence the observed performance. The REC-OneSide-NoIS (0.2) model appears to be the most effective in this experiment, achieving the highest accuracy after 400 training steps. The fluctuations in the RED-Weight model's performance might indicate sensitivity to the training process or a need for parameter tuning. The overall upward trend for all models suggests that continued training could lead to further improvements in accuracy. The data suggests that the models are converging, but further training might be needed to reach a plateau in performance. The initial difference in starting accuracy between the models could be due to different initialization strategies or pre-training.