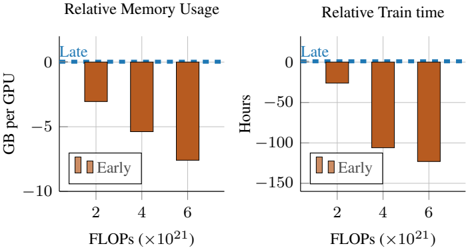
## Bar Charts: Relative Memory Usage and Relative Train Time
### Overview
The image contains two bar charts comparing "Early" and "Late" training strategies. The left chart shows "Relative Memory Usage" in GB per GPU, while the right chart shows "Relative Train time" in hours. Both charts have FLOPs (x10^21) on the x-axis.
### Components/Axes
**Left Chart: Relative Memory Usage**
* **Title:** Relative Memory Usage
* **Y-axis:** GB per GPU
* Scale: -10 to 0
* Markers: -10, -5, 0
* **X-axis:** FLOPs (x10^21)
* Categories: 2, 4, 6
* **Legend:**
* "Early": Brown bars
* **Horizontal Line:** Dashed blue line at 0, labeled "Late"
**Right Chart: Relative Train time**
* **Title:** Relative Train time
* **Y-axis:** Hours
* Scale: -150 to 0
* Markers: -150, -100, -50, 0
* **X-axis:** FLOPs (x10^21)
* Categories: 2, 4, 6
* **Legend:**
* "Early": Brown bars
* **Horizontal Line:** Dashed blue line at 0, labeled "Late"
### Detailed Analysis
**Left Chart: Relative Memory Usage**
* **Early (Brown Bars):**
* At 2 FLOPs: Approximately -3 GB per GPU
* At 4 FLOPs: Approximately -5.5 GB per GPU
* At 6 FLOPs: Approximately -8 GB per GPU
* Trend: Memory usage decreases (becomes more negative) as FLOPs increase.
**Right Chart: Relative Train time**
* **Early (Brown Bars):**
* At 2 FLOPs: Approximately -30 GB per GPU
* At 4 FLOPs: Approximately -105 GB per GPU
* At 6 FLOPs: Approximately -130 GB per GPU
* Trend: Train time decreases (becomes more negative) as FLOPs increase.
### Key Observations
* In both charts, the "Early" training strategy consistently uses less memory and takes less time than the "Late" strategy (represented by the 0 line).
* The difference between "Early" and "Late" becomes more pronounced as FLOPs increase.
### Interpretation
The charts suggest that the "Early" training strategy is more efficient in terms of both memory usage and training time compared to the "Late" strategy. The efficiency gain of the "Early" strategy increases with higher computational demands (FLOPs). This could be due to the "Early" strategy optimizing resource allocation or convergence speed as the complexity of the training task grows. The data implies that for computationally intensive tasks, adopting the "Early" training strategy could lead to significant resource savings and faster training cycles.