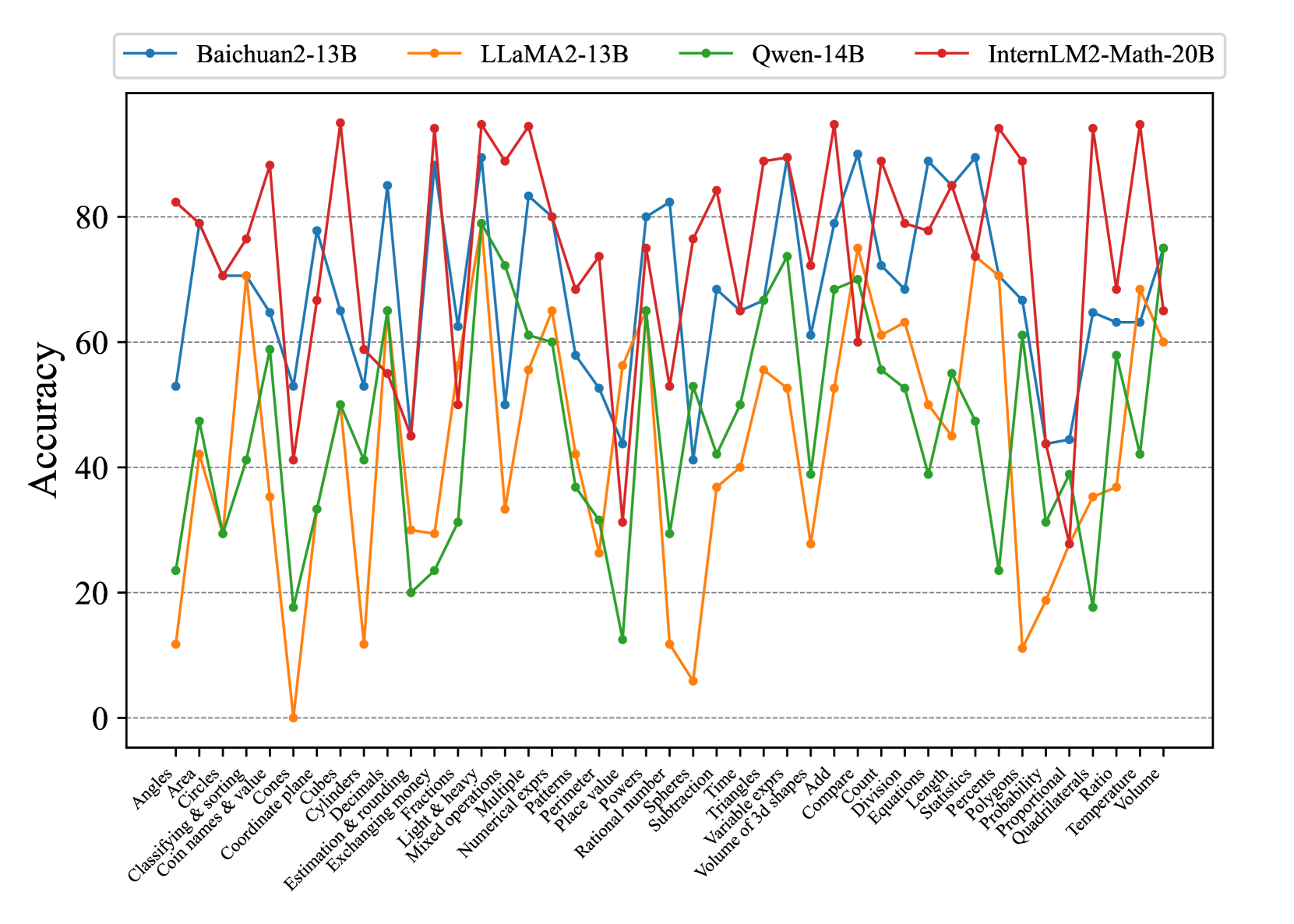
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four large language models – Baichuan2-13B, LLaMA2-13B, Qwen-14B, and InternLM2-Math-20B – across a range of mathematical problem types. The x-axis represents different math concepts, and the y-axis represents the accuracy score, ranging from 0 to 100.
### Components/Axes
* **X-axis Title:** Math Concepts (Categories)
* **Y-axis Title:** Accuracy
* **Y-axis Scale:** 0 to 100, with increments of 10.
* **Legend:** Located at the top of the chart, horizontally aligned.
* Baichuan2-13B (Orange)
* LLaMA2-13B (Red)
* Qwen-14B (Green)
* InternLM2-Math-20B (Teal)
* **Math Concept Categories (X-axis):** Angles, Classifying & sorting, Circles, Cones, Coordinate plane, Cylinders, Decimals, Estimation & rounding, Exchanging & multiplying, Fractions, Light & heavy, Mixed operations, Multiple, Numerical expressions, Patterns, Perimeter, Place value, Powers, Rational numbers, Spheres, Subtraction, Time, Triangles, Variable expressions, Volume of 3d shapes, Add, Compare, Division, Equations, Length, Statistics, Polygons, Probability, Proportional, Quadrilaterals, Ratio, Temperature, Volume.
### Detailed Analysis
The chart displays four lines, each representing a model's accuracy across the math concepts.
* **Baichuan2-13B (Orange):** The line fluctuates significantly. It starts at approximately 75, dips to around 25, then rises again to approximately 85, and ends around 60.
* **LLaMA2-13B (Red):** This line generally stays between 60 and 90. It begins at around 80, dips to approximately 60, rises to around 90, and ends around 65.
* **Qwen-14B (Green):** This line exhibits the most variability, with large swings in accuracy. It starts at approximately 30, peaks around 80, and ends around 20.
* **InternLM2-Math-20B (Teal):** This line is relatively stable, generally staying between 60 and 85. It begins at approximately 70, rises to around 85, and ends around 70.
Here's a breakdown of approximate accuracy values for specific concepts:
| Math Concept | Baichuan2-13B | LLaMA2-13B | Qwen-14B | InternLM2-Math-20B |
| ---------------------- | ------------- | ---------- | -------- | -------------------- |
| Angles | ~75 | ~80 | ~40 | ~70 |
| Circles | ~65 | ~70 | ~30 | ~75 |
| Cones | ~55 | ~60 | ~20 | ~65 |
| Coordinate plane | ~80 | ~85 | ~60 | ~80 |
| Decimals | ~85 | ~90 | ~70 | ~85 |
| Estimation & rounding | ~70 | ~75 | ~50 | ~70 |
| Fractions | ~60 | ~65 | ~40 | ~60 |
| Mixed operations | ~30 | ~40 | ~10 | ~40 |
| Patterns | ~70 | ~80 | ~50 | ~75 |
| Perimeter | ~60 | ~70 | ~30 | ~65 |
| Probability | ~50 | ~60 | ~20 | ~55 |
| Volume | ~60 | ~65 | ~20 | ~60 |
### Key Observations
* Qwen-14B demonstrates the highest degree of variance in accuracy, suggesting it may be more sensitive to the specific type of math problem.
* LLaMA2-13B and InternLM2-Math-20B generally exhibit more consistent performance across the tested concepts.
* Baichuan2-13B shows a strong performance on decimals, but struggles with mixed operations.
* All models show lower accuracy on "Mixed operations" and "Fractions" compared to other concepts.
* InternLM2-Math-20B consistently performs well, but doesn't reach the peak accuracy of LLaMA2-13B on certain tasks.
### Interpretation
The chart provides a comparative analysis of the mathematical reasoning capabilities of four large language models. The varying accuracy scores across different math concepts highlight the strengths and weaknesses of each model. The significant fluctuations in Qwen-14B's performance suggest it may be more prone to errors or require more specialized training for certain mathematical tasks. The relatively stable performance of LLaMA2-13B and InternLM2-Math-20B indicates a more robust understanding of mathematical principles. The lower accuracy scores on "Mixed operations" and "Fractions" across all models suggest these areas may require further improvement in language model training. The data suggests that while these models are capable of solving math problems, their performance is highly dependent on the specific problem type and the model's underlying architecture and training data. The InternLM2-Math-20B model, specifically designed for mathematical tasks, shows promising results, but further research is needed to optimize its performance and address its limitations.