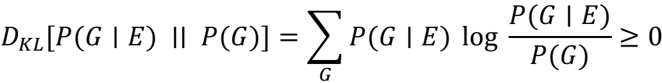## Mathematical Equation: Kullback-Leibler Divergence Formula
### Overview
The image contains a mathematical equation representing the **Kullback-Leibler (KL) divergence** between two probability distributions: \( P(G|E) \) and \( P(G) \). The equation is:
\[
D_{KL}[P(G|E) || P(G)] = \sum_G P(G|E) \log \frac{P(G|E)}{P(G)} \geq 0
\]
### Components/Axes
- **Left-hand side (LHS):**
- \( D_{KL}[P(G|E) || P(G)] \): Represents the KL divergence between the conditional probability \( P(G|E) \) and the marginal probability \( P(G) \).
- \( || \): Denotes the divergence operator (Kullback-Leibler divergence).
- **Right-hand side (RHS):**
- \( \sum_G \): Summation over all possible values of \( G \).
- \( P(G|E) \): Conditional probability of \( G \) given event \( E \).
- \( \log \frac{P(G|E)}{P(G)} \): Logarithmic ratio of the conditional probability to the marginal probability.
- \( \geq 0 \): Indicates the KL divergence is non-negative.
### Detailed Analysis
1. **Variables and Notation:**
- \( G \): A discrete random variable (e.g., a hypothesis, category, or outcome).
- \( E \): An observed event or evidence.
- \( P(G|E) \): Probability of \( G \) given \( E \).
- \( P(G) \): Prior probability of \( G \) (independent of \( E \)).
2. **Structure of the Equation:**
- The KL divergence measures how much \( P(G|E) \) "diverges" from \( P(G) \).
- The summation \( \sum_G \) aggregates contributions across all possible values of \( G \).
- The logarithmic term \( \log \frac{P(G|E)}{P(G)} \) quantifies the relative difference between the two distributions for each \( G \).
3. **Inequality Constraint:**
- \( \geq 0 \): The KL divergence is always non-negative, a fundamental property of this measure. Equality holds **only if** \( P(G|E) = P(G) \) for all \( G \), meaning \( E \) provides no information about \( G \).
### Key Observations
- The equation explicitly defines the KL divergence as a **sum of weighted logarithmic differences**.
- The non-negativity constraint (\( \geq 0 \)) is critical in applications like information theory, machine learning, and statistics, where KL divergence is used to quantify uncertainty or information gain.
- The conditional probability \( P(G|E) \) is weighted by its own magnitude in the summation, emphasizing larger discrepancies more heavily.
### Interpretation
- **What the equation demonstrates:**
The KL divergence quantifies the "distance" between two probability distributions. Here, it compares the posterior distribution \( P(G|E) \) (updated with evidence \( E \)) to the prior distribution \( P(G) \). The result \( \geq 0 \) confirms that updating beliefs with evidence cannot decrease uncertainty (unless \( E \) is irrelevant).
- **Relationships between elements:**
- \( P(G|E) \) and \( P(G) \) are linked through Bayes' theorem, though the equation does not explicitly invoke it.
- The summation ensures the divergence accounts for all possible outcomes of \( G \), making it a global measure of divergence.
- **Notable properties:**
- If \( P(G|E) = P(G) \) for all \( G \), the divergence is zero (no information gain).
- The logarithmic term penalizes deviations between the distributions, with larger discrepancies contributing more to the divergence.
- **Applications:**
- Used in **information theory** to measure information content.
- In **machine learning**, it appears in variational inference and model selection.
- In **statistics**, it quantifies the difference between empirical and theoretical distributions.
This equation is foundational for understanding how evidence \( E \) updates beliefs about \( G \), with the KL divergence serving as a mathematical tool to formalize this process.