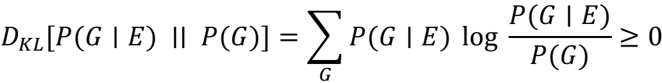## Mathematical Expression: Kullback-Leibler Divergence
### Overview
The image presents a mathematical expression defining the Kullback-Leibler (KL) divergence between two probability distributions.
### Components/Axes
* **Left-hand side:** `DKL[P(G | E) || P(G)]` represents the KL divergence between the conditional probability distribution P(G | E) and the probability distribution P(G).
* **Summation:** `Σ` indicates a summation over all possible values of G. The subscript `G` below the summation symbol specifies the variable over which the summation is performed.
* **Logarithmic term:** `log(P(G | E) / P(G))` represents the logarithm of the ratio of the conditional probability P(G | E) to the probability P(G).
* **Right-hand side:** `≥ 0` indicates that the KL divergence is always greater than or equal to zero.
### Detailed Analysis or Content Details
The equation is:
`DKL[P(G | E) || P(G)] = ΣG P(G | E) log(P(G | E) / P(G)) ≥ 0`
Where:
* `DKL[P(G | E) || P(G)]` is the Kullback-Leibler divergence of `P(G | E)` from `P(G)`.
* `P(G | E)` is the conditional probability of `G` given `E`.
* `P(G)` is the probability of `G`.
* `ΣG` denotes the sum over all possible values of `G`.
* `log` is the logarithm function (base not specified, but commonly natural logarithm).
### Key Observations
* The KL divergence is a measure of how one probability distribution diverges from a second, expected probability distribution.
* The KL divergence is always non-negative.
### Interpretation
The equation defines the Kullback-Leibler divergence, a fundamental concept in information theory and machine learning. It quantifies the information lost when `P(G)` is used to approximate `P(G | E)`. The non-negativity of the KL divergence is a key property, indicating that using an approximation always results in some information loss (or no loss if the distributions are identical).