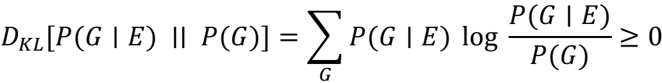\n
## Mathematical Formula: Kullback-Leibler Divergence
### Overview
The image presents a mathematical formula representing the Kullback-Leibler (KL) divergence. It's a measure of how one probability distribution diverges from a second, expected probability distribution.
### Components/Axes
The formula consists of the following elements:
* **D<sub>KL</sub>**: Represents the Kullback-Leibler divergence.
* **[P(G|E) || P(G)]**: Indicates the two probability distributions being compared. P(G|E) is the conditional probability of G given E, and P(G) is the marginal probability of G. The double vertical line (||) denotes the KL divergence operation.
* **∑<sub>G</sub>**: Represents a summation over all possible values of G.
* **P(G|E)**: The conditional probability of G given E.
* **log**: The natural logarithm.
* **P(G|E) / P(G)**: The ratio of the conditional probability to the marginal probability.
* **≥ 0**: Indicates that the KL divergence is always non-negative.
### Detailed Analysis / Content Details
The formula is:
D<sub>KL</sub>[P(G|E) || P(G)] = ∑<sub>G</sub> P(G|E) log (P(G|E) / P(G)) ≥ 0
The summation is performed over all possible values of the variable G. Each term in the summation is the product of the conditional probability P(G|E) and the natural logarithm of the ratio of the conditional probability P(G|E) to the marginal probability P(G). The result of this summation is the KL divergence, which is always greater than or equal to zero.
### Key Observations
The formula is a standard representation of the KL divergence. The use of the double vertical line notation is common in information theory. The inequality ≥ 0 highlights a key property of the KL divergence: it is always non-negative.
### Interpretation
The Kullback-Leibler divergence quantifies the information lost when P(G) is used to approximate P(G|E). In simpler terms, it measures how different two probability distributions are. A KL divergence of 0 indicates that the two distributions are identical. As the divergence increases, the distributions become more dissimilar.
This formula is fundamental in various fields, including machine learning, statistics, and information theory. It's used in model selection, feature selection, and evaluating the performance of probabilistic models. The formula's non-negativity implies that using an approximating distribution will always result in some information loss. The formula assumes that P(G|E) is defined whenever P(G) is non-zero.