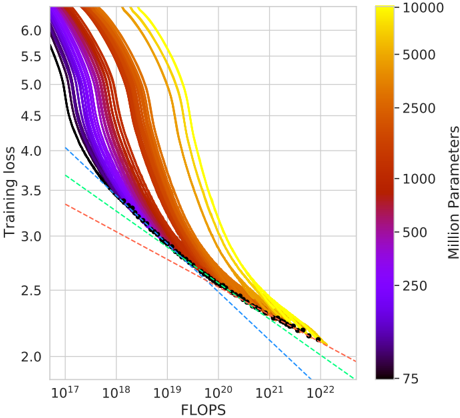
## Line Chart: Training Loss vs. FLOPS with Parameter Scaling
### Overview
The chart visualizes the relationship between computational effort (FLOPS) and training loss across neural network models with varying parameter counts (75M to 10,000M). Lines represent different model sizes, with color gradients indicating parameter scale. Theoretical performance bounds are shown as dashed lines.
### Components/Axes
- **X-axis (FLOPS)**: Logarithmic scale from 10¹⁷ to 10²².
- **Y-axis (Training Loss)**: Linear scale from 2.0 to 6.0.
- **Legend**: Right-aligned colorbar labeled "Million Parameters" (purple = 75M, yellow = 10,000M).
- **Lines**:
- Solid lines: Actual training loss trajectories.
- Dashed lines: Theoretical performance bounds (lower loss).
### Detailed Analysis
1. **Parameter Groups**:
- **75M (Purple)**: Starts at ~5.8 loss (10¹⁷ FLOPS), ends at ~2.3 (10²² FLOPS). Steepest decline.
- **250M (Dark Red)**: Starts at ~5.6, ends at ~2.2. Slightly less steep than 75M.
- **1,000M (Orange)**: Starts at ~5.4, ends at ~2.1. Gradual decline.
- **5,000M (Light Orange)**: Starts at ~5.2, ends at ~2.05. Moderate slope.
- **10,000M (Yellow)**: Starts at ~5.0, ends at ~2.0. Shallowest decline.
2. **Theoretical Bounds**:
- **Dashed Blue Line**: Theoretical minimum loss (~2.0) across all FLOPS.
- **Dashed Red Line**: Upper bound (~3.5) for low-resource models.
3. **Data Points**:
- All lines converge near 10²² FLOPS, with loss approaching ~2.0–2.3.
- Higher-parameter models (yellow/orange) achieve lower loss at equivalent FLOPS.
### Key Observations
- **Performance Scaling**: Larger models (10,000M) achieve ~20% lower loss than smaller models (75M) at the same FLOPS.
- **Efficiency Tradeoff**: Theoretical bounds suggest diminishing returns beyond ~10²² FLOPS.
- **Color Consistency**: Legend colors match line hues precisely (e.g., yellow = 10,000M).
### Interpretation
The data demonstrates that increasing model size improves training efficiency, but with diminishing returns. At 10²² FLOPS, even the largest models (10,000M) only reduce loss by ~0.5 compared to smaller models. Theoretical bounds imply that current architectures cannot fully exploit computational resources, suggesting opportunities for algorithmic improvements. The convergence of lines at high FLOPS highlights the importance of optimizing both model scale and computational investment.