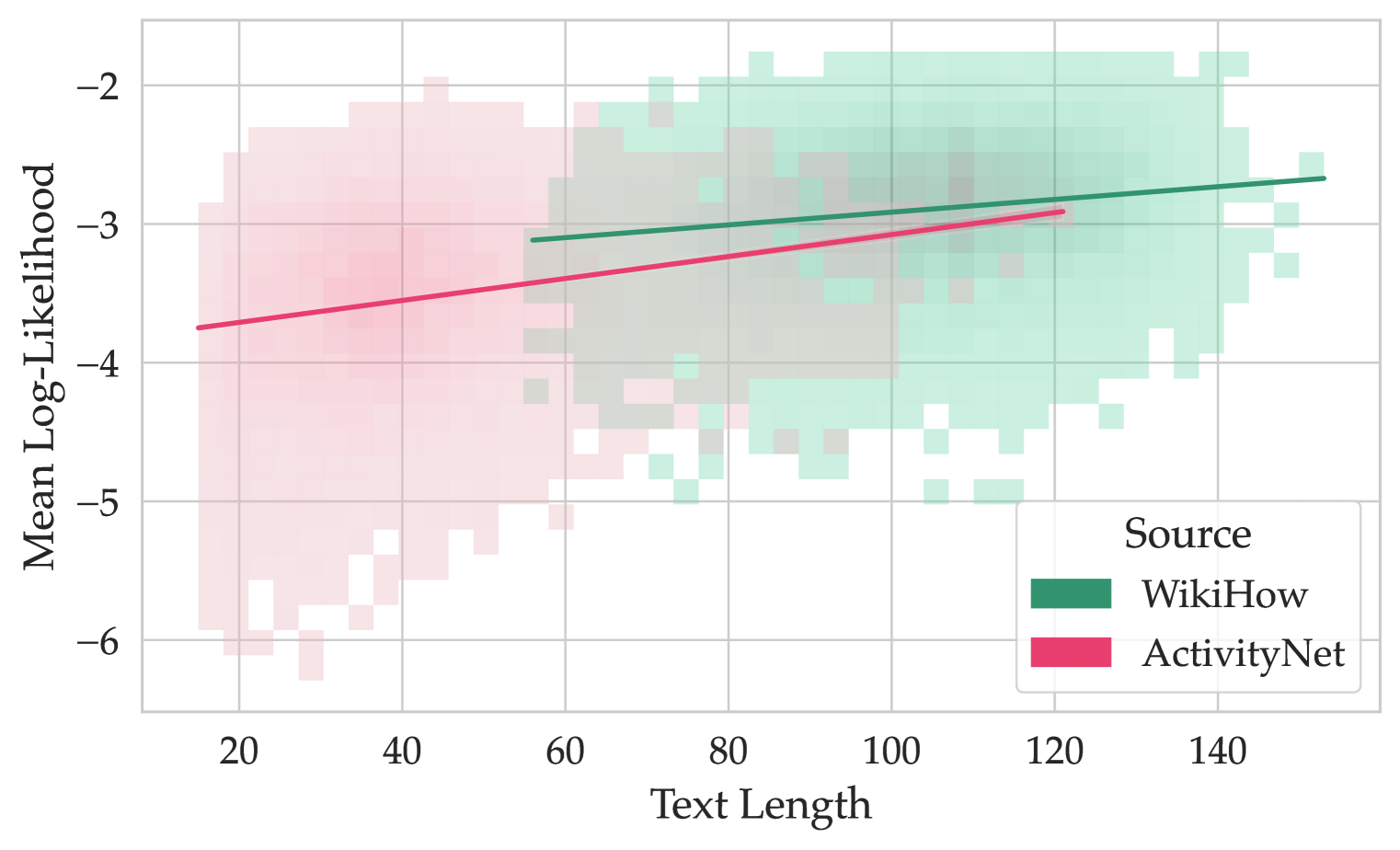
## Scatter Plot: Mean Log-Likelihood vs. Text Length
### Overview
This image presents a scatter plot visualizing the relationship between "Text Length" and "Mean Log-Likelihood" for three different data sources: WikiHow and ActivityNet. The plot uses a hexagonal binning approach to represent the density of data points.
### Components/Axes
* **X-axis:** "Text Length" ranging from approximately 10 to 150. The scale is linear.
* **Y-axis:** "Mean Log-Likelihood" ranging from approximately -6 to -2. The scale is linear.
* **Legend:** Located in the top-right corner, identifying the data sources with corresponding colors:
* WikiHow: Dark Green
* ActivityNet: Pink/Red
* **Data Representation:** Hexagonal binning is used to represent the density of data points. The color intensity within each hexagon indicates the concentration of data.
### Detailed Analysis
The plot shows three distinct distributions, each representing one of the data sources.
**1. WikiHow (Dark Green):**
* **Trend:** The data points for WikiHow generally show a slight upward trend. As text length increases, the mean log-likelihood tends to increase.
* **Data Points (Approximate):**
* At Text Length = 20, Mean Log-Likelihood ≈ -4.5
* At Text Length = 60, Mean Log-Likelihood ≈ -3.5
* At Text Length = 100, Mean Log-Likelihood ≈ -3.0
* At Text Length = 140, Mean Log-Likelihood ≈ -2.5
* **Distribution:** The data is relatively dispersed, with a higher density of points around Text Lengths of 60-140 and Mean Log-Likelihoods of -3.5 to -2.5.
**2. ActivityNet (Pink/Red):**
* **Trend:** The data points for ActivityNet show a more pronounced upward trend. As text length increases, the mean log-likelihood increases more noticeably than for WikiHow.
* **Data Points (Approximate):**
* At Text Length = 20, Mean Log-Likelihood ≈ -4.0
* At Text Length = 60, Mean Log-Likelihood ≈ -3.0
* At Text Length = 100, Mean Log-Likelihood ≈ -2.5
* At Text Length = 140, Mean Log-Likelihood ≈ -2.0
* **Distribution:** The data is concentrated in a band, with a higher density of points around Text Lengths of 20-100 and Mean Log-Likelihoods of -4.0 to -2.5.
**3. Unlabeled Data (Light Green):**
* **Trend:** The data points for the unlabeled source show a slight upward trend. As text length increases, the mean log-likelihood tends to increase.
* **Data Points (Approximate):**
* At Text Length = 20, Mean Log-Likelihood ≈ -4.0
* At Text Length = 60, Mean Log-Likelihood ≈ -3.5
* At Text Length = 100, Mean Log-Likelihood ≈ -3.0
* At Text Length = 140, Mean Log-Likelihood ≈ -2.5
* **Distribution:** The data is relatively dispersed, with a higher density of points around Text Lengths of 60-140 and Mean Log-Likelihoods of -3.5 to -2.5.
### Key Observations
* ActivityNet consistently exhibits higher mean log-likelihood values for a given text length compared to WikiHow.
* Both WikiHow and ActivityNet show a positive correlation between text length and mean log-likelihood, suggesting that longer texts are associated with higher likelihood scores.
* The unlabeled data source appears to have a similar trend to WikiHow.
### Interpretation
The plot suggests that the quality or predictability of text, as measured by mean log-likelihood, increases with text length for both WikiHow and ActivityNet. The difference in mean log-likelihood between the two sources indicates that ActivityNet texts are generally more predictable or better modeled by the underlying language model than WikiHow texts. The hexagonal binning effectively visualizes the density of data points, highlighting areas where the relationship between text length and mean log-likelihood is strongest. The upward trends for both sources suggest that longer texts provide more information for the language model to work with, leading to more accurate predictions. The unlabeled data source's similarity to WikiHow could indicate a similar type of content or a similar level of predictability.