TECHNICAL ASSET FINGERPRINT
cd4a980230cb07cd13525b58
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
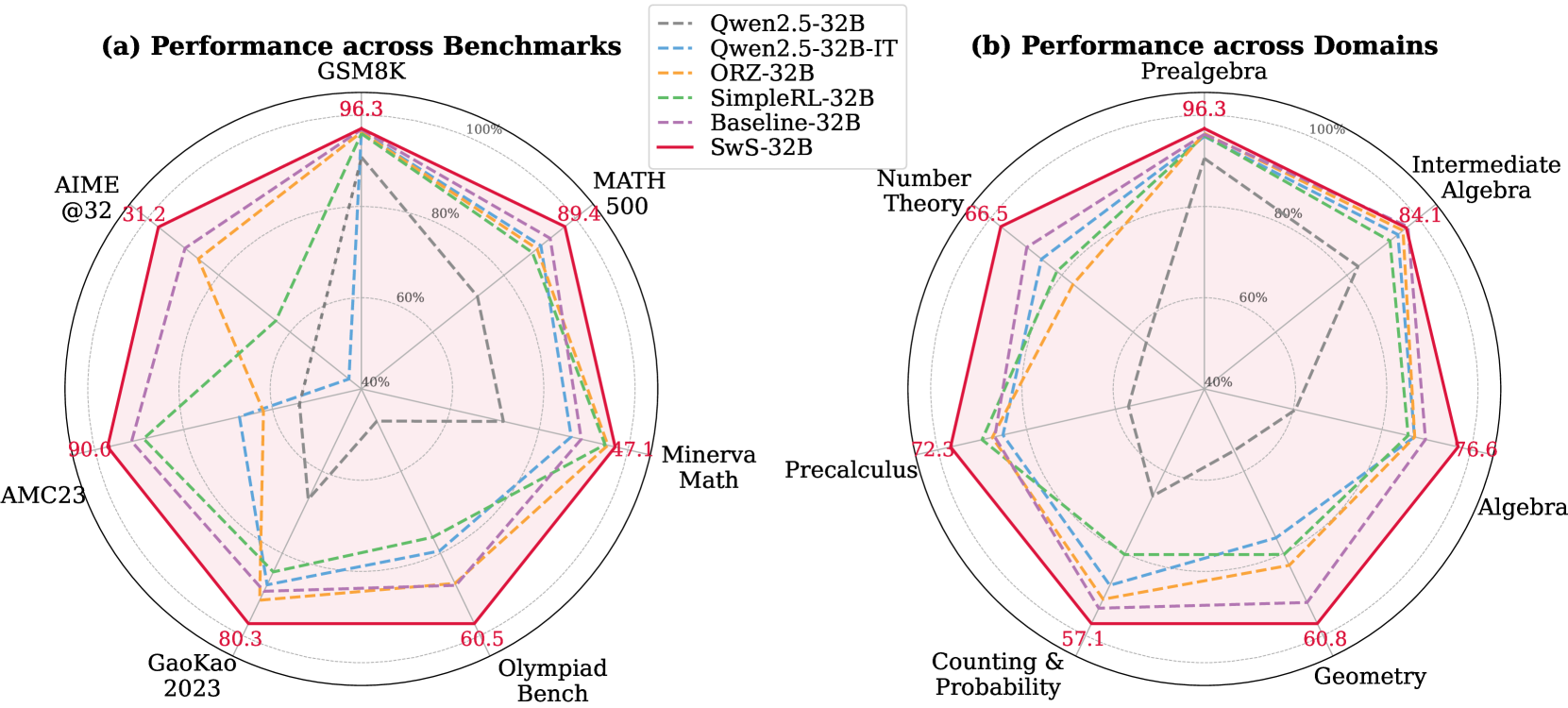
## Radar Charts: Performance Comparison
### Overview
The image presents two radar charts comparing the performance of different language models across various benchmarks and domains. Chart (a) focuses on benchmarks like GSM8K, MATH, and others, while chart (b) assesses performance across domains such as Prealgebra, Number Theory, and Algebra. The charts display the performance of six models: Qwen2.5-32B, Qwen2.5-32B-IT, ORZ-32B, SimpleRL-32B, Baseline-32B, and SwS-32B.
### Components/Axes
**General Chart Elements:**
* Each chart is a radar plot with performance scores plotted along radial axes.
* The radial axes range from approximately 0% to 100%, with concentric dotted circles indicating 40%, 60%, 80%, and 100%.
* A legend is positioned between the two charts, listing the models and their corresponding line styles and colors.
**Chart (a): Performance across Benchmarks**
* **Title:** (a) Performance across Benchmarks
* **Benchmarks (Categories):** GSM8K, MATH, Minerva Math, Olympiad Bench, GaoKao 2023, AMC23, AIME @32
* **Axis Labels and Values:**
* GSM8K: 96.3
* MATH: 89.4
* Minerva Math: 47.1
* Olympiad Bench: 60.5
* GaoKao 2023: 80.3
* AMC23: 90.0
* AIME @32: 31.2
**Chart (b): Performance across Domains**
* **Title:** (b) Performance across Domains
* **Domains (Categories):** Prealgebra, Number Theory, Intermediate Algebra, Algebra, Geometry, Counting & Probability, Precalculus
* **Axis Labels and Values:**
* Prealgebra: 96.3
* Number Theory: 66.5
* Intermediate Algebra: 84.1
* Algebra: 76.6
* Geometry: 60.8
* Counting & Probability: 57.1
* Precalculus: 72.3
**Legend (Located between the two charts):**
* Qwen2.5-32B: Gray dashed line
* Qwen2.5-32B-IT: Blue dashed line
* ORZ-32B: Orange dashed line
* SimpleRL-32B: Green dashed line
* Baseline-32B: Purple dashed line
* SwS-32B: Solid red line
### Detailed Analysis
**Chart (a): Performance across Benchmarks**
* **SwS-32B (Red solid line):** This model generally outperforms the others across most benchmarks.
* GSM8K: ~96.3
* MATH: ~89.4
* Minerva Math: ~47.1
* Olympiad Bench: ~60.5
* GaoKao 2023: ~80.3
* AMC23: ~90.0
* AIME @32: ~31.2
* **Qwen2.5-32B (Gray dashed line):** Shows relatively lower performance, especially on AIME @32 and Minerva Math.
* GSM8K: ~96.3
* MATH: ~40
* Minerva Math: ~10
* Olympiad Bench: ~30
* GaoKao 2023: ~40
* AMC23: ~40
* AIME @32: ~10
* **Qwen2.5-32B-IT (Blue dashed line):** Performance is generally better than Qwen2.5-32B but lower than SwS-32B.
* GSM8K: ~96.3
* MATH: ~80
* Minerva Math: ~40
* Olympiad Bench: ~50
* GaoKao 2023: ~70
* AMC23: ~80
* AIME @32: ~20
* **ORZ-32B (Orange dashed line):** Similar performance to Qwen2.5-32B-IT.
* GSM8K: ~96.3
* MATH: ~80
* Minerva Math: ~40
* Olympiad Bench: ~50
* GaoKao 2023: ~70
* AMC23: ~80
* AIME @32: ~20
* **SimpleRL-32B (Green dashed line):** Performance is close to ORZ-32B and Qwen2.5-32B-IT.
* GSM8K: ~96.3
* MATH: ~80
* Minerva Math: ~40
* Olympiad Bench: ~50
* GaoKao 2023: ~70
* AMC23: ~80
* AIME @32: ~20
* **Baseline-32B (Purple dashed line):** Performance is close to ORZ-32B and Qwen2.5-32B-IT.
* GSM8K: ~96.3
* MATH: ~80
* Minerva Math: ~40
* Olympiad Bench: ~50
* GaoKao 2023: ~70
* AMC23: ~80
* AIME @32: ~20
**Chart (b): Performance across Domains**
* **SwS-32B (Red solid line):** Again, this model shows the highest performance across all domains.
* Prealgebra: ~96.3
* Number Theory: ~66.5
* Intermediate Algebra: ~84.1
* Algebra: ~76.6
* Geometry: ~60.8
* Counting & Probability: ~57.1
* Precalculus: ~72.3
* **Qwen2.5-32B (Gray dashed line):** Shows the lowest performance across all domains.
* Prealgebra: ~96.3
* Number Theory: ~30
* Intermediate Algebra: ~50
* Algebra: ~40
* Geometry: ~30
* Counting & Probability: ~20
* Precalculus: ~40
* **Qwen2.5-32B-IT (Blue dashed line):** Performance is generally better than Qwen2.5-32B but lower than SwS-32B.
* Prealgebra: ~96.3
* Number Theory: ~60
* Intermediate Algebra: ~80
* Algebra: ~70
* Geometry: ~50
* Counting & Probability: ~40
* Precalculus: ~60
* **ORZ-32B (Orange dashed line):** Similar performance to Qwen2.5-32B-IT.
* Prealgebra: ~96.3
* Number Theory: ~60
* Intermediate Algebra: ~80
* Algebra: ~70
* Geometry: ~50
* Counting & Probability: ~40
* Precalculus: ~60
* **SimpleRL-32B (Green dashed line):** Performance is close to ORZ-32B and Qwen2.5-32B-IT.
* Prealgebra: ~96.3
* Number Theory: ~60
* Intermediate Algebra: ~80
* Algebra: ~70
* Geometry: ~50
* Counting & Probability: ~40
* Precalculus: ~60
* **Baseline-32B (Purple dashed line):** Performance is close to ORZ-32B and Qwen2.5-32B-IT.
* Prealgebra: ~96.3
* Number Theory: ~60
* Intermediate Algebra: ~80
* Algebra: ~70
* Geometry: ~50
* Counting & Probability: ~40
* Precalculus: ~60
### Key Observations
* **SwS-32B Dominance:** The SwS-32B model consistently achieves the highest performance across both benchmarks and domains.
* **Qwen2.5-32B Underperformance:** The Qwen2.5-32B model generally exhibits the lowest performance compared to the other models.
* **Benchmark Variability:** Performance varies significantly across different benchmarks, particularly for models other than SwS-32B. For example, performance on AIME @32 is notably lower for most models.
* **Domain Consistency:** The relative performance of models across different domains is more consistent compared to the benchmarks.
### Interpretation
The radar charts provide a clear visual comparison of the performance of different language models on various mathematical tasks. The SwS-32B model's superior performance suggests it may have architectural or training advantages that make it more effective in these domains. The Qwen2.5-32B model's lower scores indicate potential areas for improvement. The variability in performance across benchmarks highlights the diverse challenges posed by different problem types, while the consistency across domains suggests a more uniform level of competence in those areas. These insights can guide future research and development efforts to enhance the capabilities of language models in mathematical reasoning.
DECODING INTELLIGENCE...