## Diagram: Transformer Model Architecture
### Overview
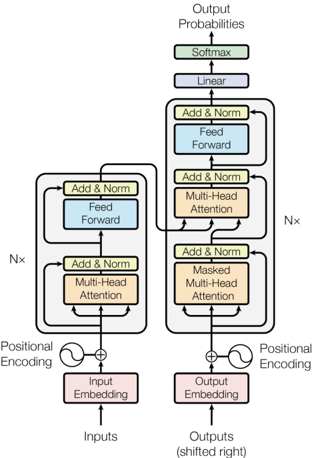
The image depicts the high-level architecture of a Transformer model, a neural network architecture commonly used in natural language processing. The diagram illustrates the encoder and decoder components, their internal layers, and the flow of information between them. It's a block diagram showing the functional components and their connections, rather than a detailed circuit or schematic.
### Components/Axes
The diagram is structured into two main vertical stacks: the Encoder (left) and the Decoder (right). Key components are labeled within rectangular blocks. The diagram includes the following labels:
* **Inputs:** Located at the bottom of the Encoder stack.
* **Outputs (shifted right):** Located at the bottom of the Decoder stack.
* **Input Embedding:** Pink block within the Encoder.
* **Output Embedding:** Pink block within the Decoder.
* **Positional Encoding:** Circular symbol with a plus sign, connected to both Input and Output Embeddings.
* **Multi-Head Attention:** Orange blocks within both Encoder and Decoder.
* **Add & Norm:** Light blue blocks within both Encoder and Decoder.
* **Feed Forward:** Light blue blocks within both Encoder and Decoder.
* **Linear:** Lavender block at the top of the Decoder.
* **Softmax:** Green block at the very top of the Decoder.
* **Output Probabilities:** Label at the top of the Decoder.
* **Nx:** Label on the right side of the diagram, indicating the number of layers.
There are no explicit axes or scales in this diagram. The diagram uses arrows to indicate the direction of data flow.
### Detailed Analysis or Content Details
The Encoder consists of a stack of 'Nx' identical layers. Each layer contains a "Multi-Head Attention" block, followed by an "Add & Norm" block, and then a "Feed Forward" block. The input to the Encoder is first passed through an "Input Embedding" layer, and then combined with "Positional Encoding" via addition.
The Decoder also consists of a stack of 'Nx' identical layers. Each layer contains a "Masked Multi-Head Attention" block, followed by an "Add & Norm" block, a "Multi-Head Attention" block, another "Add & Norm" block, and finally a "Feed Forward" block. The input to the Decoder is first passed through an "Output Embedding" layer, and then combined with "Positional Encoding" via addition. The output of the Decoder stack is then passed through a "Linear" layer and finally a "Softmax" layer to produce "Output Probabilities".
The diagram shows connections between the Encoder and Decoder. Specifically, the output of each Encoder layer is fed into each Decoder layer's second "Multi-Head Attention" block.
### Key Observations
* The Encoder and Decoder have a similar structure, both consisting of stacked layers with attention and feed-forward networks.
* The Decoder includes a "Masked Multi-Head Attention" layer, which is not present in the Encoder. This masking is crucial for autoregressive decoding, preventing the model from "looking ahead" at future tokens during training.
* The "Positional Encoding" is added to both the input embeddings of the Encoder and Decoder, providing information about the position of tokens in the sequence.
* The "Add & Norm" blocks likely represent residual connections and layer normalization, common techniques for training deep neural networks.
* The diagram does not specify the dimensions of the embeddings or the number of attention heads.
### Interpretation
This diagram illustrates the core architecture of a Transformer model, which has revolutionized the field of natural language processing. The key innovation of the Transformer is the use of self-attention mechanisms, which allow the model to weigh the importance of different parts of the input sequence when making predictions. The Encoder processes the input sequence to create a contextualized representation, while the Decoder generates the output sequence one token at a time, conditioned on the Encoder's output and the previously generated tokens. The "Nx" notation suggests that the model can be scaled by increasing the number of layers, allowing it to learn more complex relationships in the data. The diagram provides a high-level overview of the model's structure and does not delve into the details of the attention mechanism or the specific implementation of the feed-forward networks. The diagram is a conceptual representation, and actual implementations may vary. The diagram is a simplified representation of a complex system, and does not include details such as the specific activation functions used or the optimization algorithms employed during training.