TECHNICAL ASSET FINGERPRINT
cd70a0411843baab193aac62
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
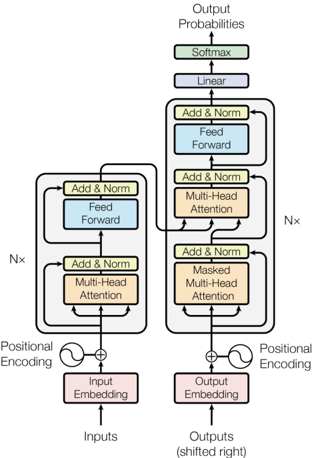
## Diagram: Transformer Neural Network Architecture (Encoder-Decoder)
### Overview
This image is a technical schematic diagram illustrating the architecture of a Transformer model, a foundational neural network design primarily used in natural language processing. The diagram is divided into two symmetrical vertical stacks: the **Encoder** on the left and the **Decoder** on the right. It details the flow of data from input tokens to output probabilities, highlighting the core components of self-attention and feed-forward networks.
### Components/Axes
The diagram is a flowchart with labeled rectangular blocks, arrows indicating data flow, and mathematical symbols. There are no traditional chart axes. The key components are:
**Encoder (Left Stack):**
* **Inputs**: The entry point at the bottom left.
* **Input Embedding**: A pink block that converts input tokens into vectors.
* **Positional Encoding**: Represented by a sine wave symbol (`∿`) added (`⊕`) to the embedding to provide sequence order information.
* **Multi-Head Attention**: An orange block where the model attends to different parts of the input sequence.
* **Add & Norm**: A yellow block representing a residual connection followed by layer normalization. This appears after both the attention and feed-forward layers.
* **Feed Forward**: A blue block containing a position-wise fully connected network.
* **Nx**: A label on the left side indicating that the entire block of Multi-Head Attention, Add & Norm, Feed Forward, and Add & Norm is repeated `N` times (stacked).
**Decoder (Right Stack):**
* **Outputs (shifted right)**: The entry point at the bottom right.
* **Output Embedding**: A pink block that converts target tokens into vectors.
* **Positional Encoding**: Similar to the encoder, added to the output embedding.
* **Masked Multi-head Attention**: An orange block. The "Masked" label indicates it prevents positions from attending to subsequent positions, preserving auto-regressive property.
* **Add & Norm**: Yellow blocks following each sub-layer.
* **Multi-Head Attention**: A second orange attention block in the decoder. This one performs encoder-decoder attention, allowing the decoder to focus on relevant parts of the encoder's output.
* **Feed Forward**: A blue block, similar to the encoder's.
* **Nx**: A label on the right side indicating the decoder block (Masked Attention, Add & Norm, Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm) is also repeated `N` times.
**Final Output Layers (Top Center):**
* **Linear**: A purple block that projects the decoder's final output vector into a larger vector the size of the vocabulary.
* **Softmax**: A green block that converts the linear output into a probability distribution.
* **Output Probabilities**: The final output at the very top.
**Data Flow & Connections:**
* Solid black arrows show the primary forward flow of data.
* Curved arrows bypassing blocks (e.g., from before "Multi-Head Attention" to after "Add & Norm") represent **residual connections**.
* The output of the encoder stack feeds into the middle of the decoder stack, specifically into the second "Multi-Head Attention" block.
### Detailed Analysis
The diagram meticulously details the data transformation pipeline:
1. **Input Pathway**: Raw `Inputs` → `Input Embedding` → combined with `Positional Encoding` → enters the first `Nx` encoder block.
2. **Encoder Block (xN)**: The embedded signal undergoes:
* `Multi-Head Attention` (self-attention).
* Residual connection and normalization (`Add & Norm`).
* `Feed Forward` network processing.
* Another residual connection and normalization (`Add & Norm`).
* The output of one block becomes the input to the next, repeated `N` times.
3. **Decoder Pathway**: Raw `Outputs (shifted right)` → `Output Embedding` → combined with `Positional Encoding` → enters the first `Nx` decoder block.
4. **Decoder Block (xN)**: The embedded signal undergoes a more complex sequence:
* `Masked Multi-head Attention` (prevents looking ahead).
* Residual connection and normalization (`Add & Norm`).
* **Encoder-Decoder Attention**: A `Multi-Head Attention` layer that takes two inputs: the output from the previous decoder sub-layer (query) and the final output of the encoder stack (key and value).
* Residual connection and normalization (`Add & Norm`).
* `Feed Forward` network processing.
* Final residual connection and normalization (`Add & Norm`).
5. **Output Generation**: The final output from the `Nx` decoder stack is passed through a `Linear` layer, then a `Softmax` function, resulting in the final `Output Probabilities` for the next token in the sequence.
### Key Observations
* **Symmetry and Asymmetry**: The encoder and decoder share a similar macro-structure of attention + feed-forward networks with residual connections. The key asymmetries are the decoder's initial **masked** attention and its additional **encoder-decoder attention** layer.
* **Residual Connections**: The ubiquitous `Add & Norm` blocks with their bypass arrows are a critical design feature, facilitating gradient flow and enabling the training of very deep networks (`Nx` can be large, e.g., 6, 12, or more).
* **Information Bottleneck**: The encoder compresses the entire input sequence into a continuous representation. The decoder then uses this representation, combined with its own previously generated outputs, to produce the sequence auto-regressively.
* **Positional Awareness**: The explicit `Positional Encoding` added to embeddings is necessary because the core operations (attention, feed-forward) are permutation-invariant and have no inherent sense of sequence order.
### Interpretation
This diagram is a canonical representation of the **Transformer architecture** introduced in the paper "Attention Is All You Need." It visually explains the model's core innovation: replacing recurrent layers (like LSTMs) with **self-attention mechanisms**, allowing for significantly more parallelization during training.
The architecture demonstrates a sophisticated balance:
* **Encoder Role**: Builds a deep, contextual understanding of the *entire input sequence*.
* **Decoder Role**: Generates the output sequence one token at a time, using both its own prior predictions (via masked attention) and the encoder's understanding of the source (via encoder-decoder attention).
The `Nx` stacking indicates the model's depth, which is key to its capacity to learn complex language patterns. The final `Linear` + `Softmax` layers are a standard pattern for converting hidden states into interpretable predictions over a discrete vocabulary.
This schematic is not just a flowchart; it's a blueprint for a system that processes information in parallel, maintains context through attention, and uses deep residual learning—principles that have made Transformers the dominant architecture in modern AI for tasks from translation to text generation and beyond.
DECODING INTELLIGENCE...