## Transformer Model Architecture Diagram
### Overview
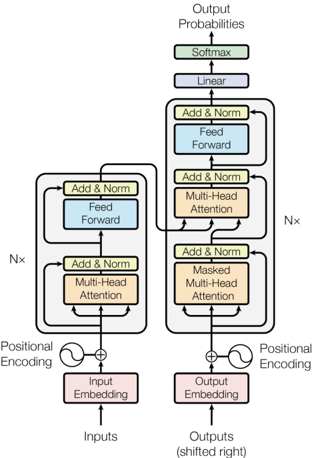
The diagram illustrates the architecture of a transformer model, showing the flow of data from inputs to outputs through encoder and decoder stacks. Key components include positional encoding, multi-head attention mechanisms, feed-forward networks, and normalization layers. The output is processed through linear and softmax layers to generate probabilities.
### Components/Axes
- **Inputs**: Raw input sequence (e.g., tokens in a sentence).
- **Outputs (shifted right)**: Target sequence with a rightward shift for autoregressive generation.
- **Positional Encoding**: Added to input/output embeddings to encode sequence order.
- **Input Embedding**: Converts input tokens into dense vectors.
- **Output Embedding**: Converts output tokens into dense vectors.
- **Encoder Stack**: Contains N× layers with:
- Multi-Head Attention
- Feed-Forward Network
- Add & Norm (residual connection + layer normalization)
- **Decoder Stack**: Contains N× layers with:
- Masked Multi-Head Attention (prevents attending to future tokens)
- Multi-Head Attention (attends to encoder outputs)
- Feed-Forward Network
- Add & Norm
- **Output Processing**: Linear layer followed by Softmax to produce output probabilities.
### Detailed Analysis
- **Positional Encoding**: Applied to both input and output embeddings to preserve sequence order information.
- **Encoder**: Processes input sequences in parallel using self-attention and feed-forward networks. Residual connections and layer normalization stabilize training.
- **Decoder**: Generates output sequences autoregressively. Masked attention ensures tokens only attend to previous positions. Cross-attention connects decoder to encoder outputs.
- **Normalization**: Add & Norm layers (residual + layer norm) appear after each sub-layer (attention/feed-forward) to improve gradient flow.
- **Output**: Final output passes through a linear projection and softmax to compute token probabilities.
### Key Observations
1. **Masked Attention in Decoder**: Critical for autoregressive generation, preventing the model from "cheating" by seeing future tokens during training.
2. **Parallel Processing**: Encoder processes all input tokens simultaneously via self-attention, enabling efficient computation.
3. **Stacked Layers**: N× indicates multiple identical layers (depth), allowing the model to capture complex patterns through depth.
4. **Shifted Outputs**: Output sequence is shifted right to align with the decoder's autoregressive nature.
### Interpretation
This architecture demonstrates the transformer's ability to handle sequential data through self-attention mechanisms. The encoder-decoder structure enables tasks like machine translation, where the encoder processes the source language and the decoder generates the target language. Masked attention in the decoder ensures the model learns to predict tokens based solely on prior context, mimicking human language generation. The use of residual connections and layer normalization addresses vanishing gradient problems, enabling training of deep networks. The softmax output provides a probability distribution over the vocabulary, essential for sequence prediction tasks. The architecture's design balances parallel computation (attention) with sequential processing (feed-forward), making it highly effective for complex sequence modeling.