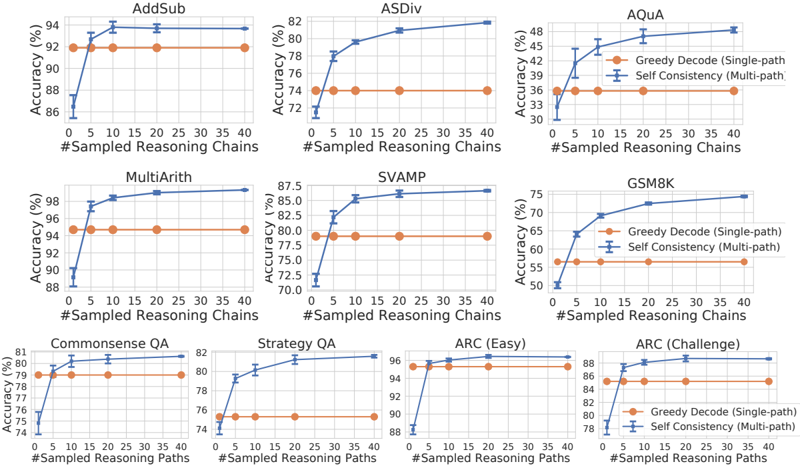
## Line Graphs: Accuracy Comparison Across Tasks
### Overview
The image contains 9 line graphs comparing the accuracy of two reasoning methods ("Greedy Decode" and "Self Consistency") across different tasks (e.g., AddSub, ASDiv, AQuA). Each graph plots accuracy (%) against the number of sampled reasoning chains/paths (0–40). The graphs are arranged in a 3x3 grid, with tasks labeled at the top of each subplot.
---
### Components/Axes
- **X-Axes**:
- Labeled "#Sampled Reasoning Chains" (for most graphs) or "#Sampled Reasoning Paths" (for QA tasks).
- Scale: 0 to 40 in increments of 5.
- **Y-Axes**:
- Labeled "Accuracy (%)".
- Scale: Varies by task (e.g., 70–98% for AddSub, 30–48% for AQuA).
- **Legends**:
- Positioned at the top-right of each graph.
- Colors:
- Orange: "Greedy Decode (Single-path)"
- Blue: "Self Consistency (Multi-path)"
- **Task Labels**:
- Top of each graph (e.g., "AddSub", "ASDiv", "AQuA", "MultiArith", "SVAMP", "GSM8K", "Commonsense QA", "Strategy QA", "ARC (Easy)", "ARC (Challenge)").
---
### Detailed Analysis
#### AddSub
- **Greedy Decode**: Flat line at ~92% accuracy across all sampled chains.
- **Self Consistency**: Starts at ~86% (0 chains), rises sharply to ~94% by 5 chains, then plateaus.
#### ASDiv
- **Greedy Decode**: Flat line at ~74% accuracy.
- **Self Consistency**: Starts at ~72%, increases gradually to ~82% by 40 chains.
#### AQuA
- **Greedy Decode**: Flat line at ~36% accuracy.
- **Self Consistency**: Starts at ~33%, rises to ~48% by 40 chains.
#### MultiArith
- **Greedy Decode**: Flat line at ~94% accuracy.
- **Self Consistency**: Starts at ~90%, increases to ~98% by 40 chains.
#### SVAMP
- **Greedy Decode**: Flat line at ~75% accuracy.
- **Self Consistency**: Starts at ~70%, rises to ~87.5% by 40 chains.
#### GSM8K
- **Greedy Decode**: Flat line at ~65% accuracy.
- **Self Consistency**: Starts at ~55%, increases to ~75% by 40 chains.
#### Commonsense QA
- **Greedy Decode**: Flat line at ~78% accuracy.
- **Self Consistency**: Starts at ~74%, rises to ~81% by 40 chains.
#### Strategy QA
- **Greedy Decode**: Flat line at ~80% accuracy.
- **Self Consistency**: Starts at ~76%, increases to ~82% by 40 chains.
#### ARC (Easy)
- **Greedy Decode**: Flat line at ~94% accuracy.
- **Self Consistency**: Starts at ~88%, rises to ~96% by 40 chains.
#### ARC (Challenge)
- **Greedy Decode**: Flat line at ~84% accuracy.
- **Self Consistency**: Starts at ~78%, increases to ~88% by 40 chains.
---
### Key Observations
1. **Self Consistency (blue) outperforms Greedy Decode (orange)** in all tasks where the number of sampled chains increases. The gap widens as more chains are sampled.
2. **Tasks with higher baseline accuracy** (e.g., AddSub, MultiArith) show smaller improvements for Self Consistency compared to tasks with lower baselines (e.g., AQuA, GSM8K).
3. **ARC (Challenge)** has the largest absolute improvement (~10% accuracy gain) for Self Consistency.
4. **Greedy Decode** remains static across all tasks, suggesting it does not benefit from additional reasoning chains.
---
### Interpretation
The data demonstrates that **Self Consistency (multi-path reasoning)** consistently improves accuracy as more reasoning chains are sampled, while **Greedy Decode (single-path)** remains unchanged. This implies:
- Multi-path reasoning explores diverse logical paths, enhancing performance in complex tasks.
- Greedy Decode’s static performance highlights its limitation in handling tasks requiring iterative or adaptive reasoning.
- Tasks like AQuA and GSM8K (with lower baseline accuracy) benefit more from multi-path exploration, suggesting they involve higher reasoning complexity.
The results align with prior work showing that self-consistency improves robustness in language models by reducing reliance on single, potentially error-prone reasoning paths.