\n
## Bar Chart: Radiological and Nuclear Expert Knowledge
### Overview
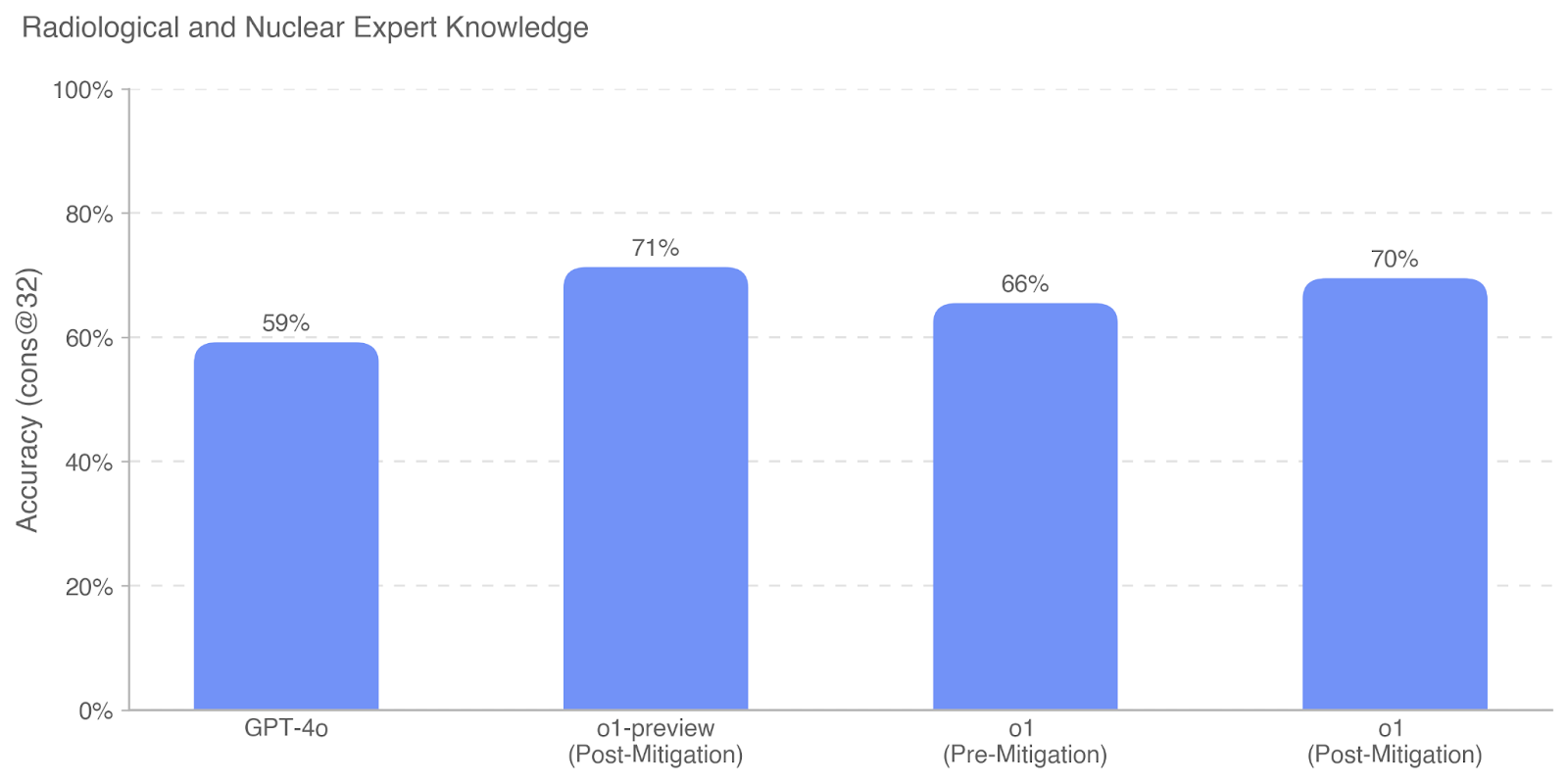
This is a bar chart comparing the accuracy of GPT-4o and different versions of "o1" (likely a model or system) on tasks requiring radiological and nuclear expert knowledge. Accuracy is measured as "cons@32", which likely refers to the percentage of times the correct answer was within the top 32 considered options. The chart shows accuracy both before and after mitigation steps were applied to the "o1" model.
### Components/Axes
* **Title:** Radiological and Nuclear Expert Knowledge
* **X-axis:** Model/Version (GPT-4o, o1-preview (Post-Mitigation), o1 (Pre-Mitigation), o1 (Post-Mitigation))
* **Y-axis:** Accuracy (cons@32) - Scale ranges from 0% to 100%, with increments of 20%.
* **Bars:** Represent the accuracy scores for each model/version. All bars are the same blue color.
### Detailed Analysis
The chart presents four data points, each represented by a vertical bar.
* **GPT-4o:** The bar for GPT-4o reaches approximately 59% accuracy.
* **o1-preview (Post-Mitigation):** This bar reaches approximately 71% accuracy. The trend is a significant increase from GPT-4o.
* **o1 (Pre-Mitigation):** This bar reaches approximately 66% accuracy. The trend is a decrease from the "o1-preview" version.
* **o1 (Post-Mitigation):** This bar reaches approximately 70% accuracy. The trend is an increase from the "o1 (Pre-Mitigation)" version, but slightly lower than the "o1-preview" version.
### Key Observations
* The "o1-preview" version, after mitigation, demonstrates the highest accuracy at approximately 71%.
* GPT-4o has the lowest accuracy at approximately 59%.
* Mitigation appears to improve the accuracy of the "o1" model, as the "Post-Mitigation" version consistently outperforms the "Pre-Mitigation" version.
* The difference in accuracy between the "o1-preview" and "o1 (Post-Mitigation)" is relatively small (approximately 1%).
### Interpretation
The data suggests that the "o1" model, particularly the "preview" version with post-mitigation, performs better than GPT-4o on tasks requiring radiological and nuclear expert knowledge, as measured by the "cons@32" metric. The application of mitigation techniques to the "o1" model consistently improves its accuracy. The slight difference between the "o1-preview" and "o1 (Post-Mitigation)" versions could indicate that the mitigation techniques used in the "preview" version were slightly more effective, or that there are other factors influencing the performance of the "o1" model. The "cons@32" metric implies a ranking or selection process, where the model is evaluated on whether the correct answer appears within its top 32 predictions. This suggests the task is not simply about identifying the single best answer, but about ensuring the correct answer is considered among a set of plausible options. The data does not provide information about the nature of the tasks or the specific types of radiological and nuclear knowledge being tested.