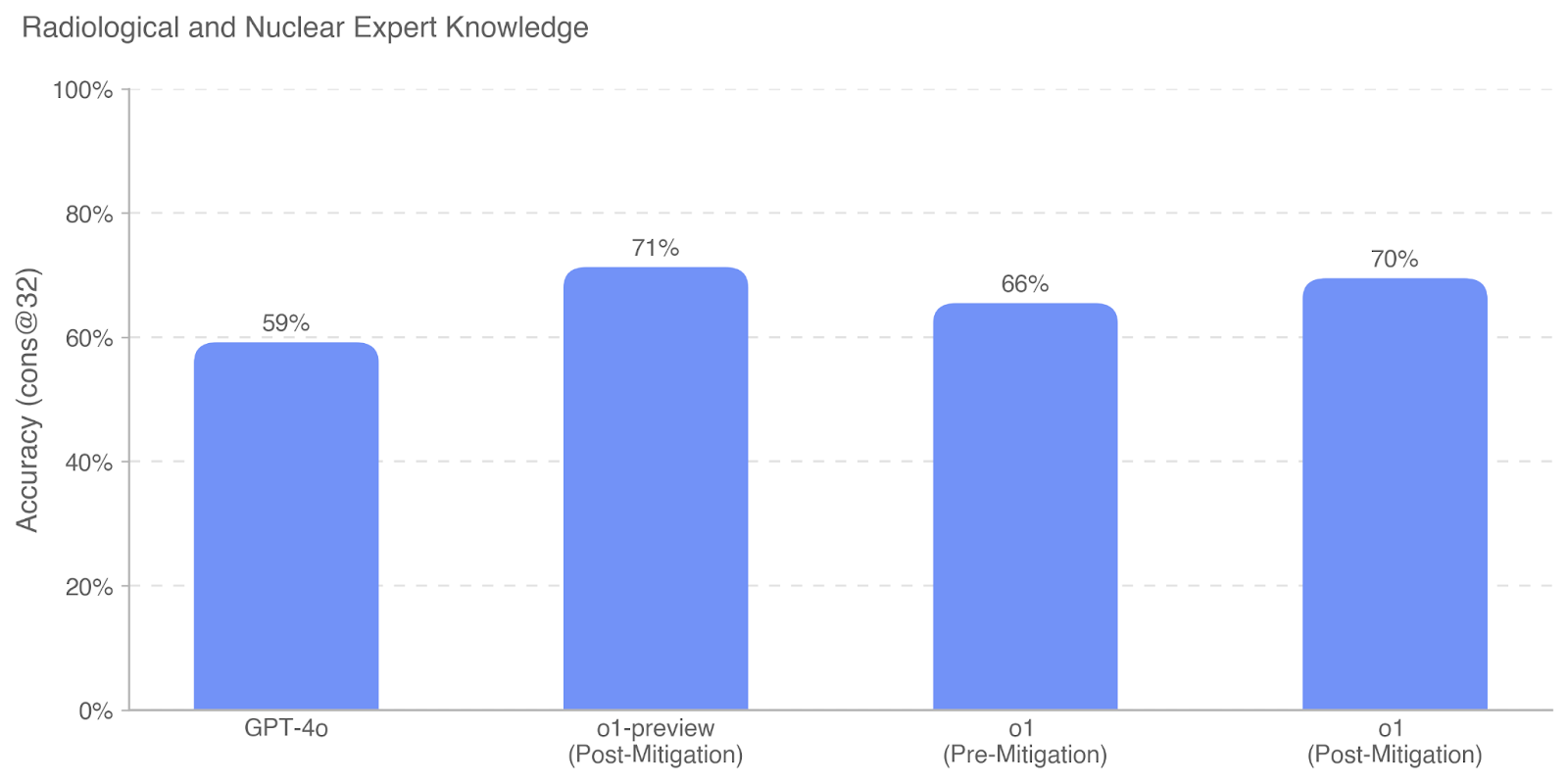
## Bar Chart: Radiological and Nuclear Expert Knowledge
### Overview
This is a vertical bar chart comparing the performance accuracy of four different AI models or model versions on a task related to "Radiological and Nuclear Expert Knowledge." The chart displays a single metric, "Accuracy (cons @ 32)," as a percentage for each category.
### Components/Axes
* **Chart Title:** "Radiological and Nuclear Expert Knowledge" (located at the top-left).
* **Y-Axis:**
* **Label:** "Accuracy (cons @ 32)" (rotated vertically on the left side).
* **Scale:** Linear scale from 0% to 100%.
* **Major Tick Marks:** 0%, 20%, 40%, 60%, 80%, 100%.
* **Grid Lines:** Horizontal dashed lines extend from each major tick mark across the chart.
* **X-Axis:**
* **Categories (from left to right):**
1. GPT-4o
2. o1-preview (Post-Mitigation)
3. o1 (Pre-Mitigation)
4. o1 (Post-Mitigation)
* **Data Series:** A single series represented by four solid blue bars. There is no separate legend, as each bar is directly labeled on the x-axis.
* **Data Labels:** The exact percentage value is displayed centered above each bar.
### Detailed Analysis
The chart presents the following specific data points:
1. **GPT-4o:** The bar reaches a height corresponding to **59%** accuracy.
2. **o1-preview (Post-Mitigation):** This is the tallest bar, indicating the highest accuracy at **71%**.
3. **o1 (Pre-Mitigation):** This bar shows an accuracy of **66%**.
4. **o1 (Post-Mitigation):** This bar shows an accuracy of **70%**.
**Trend Verification:** The visual trend shows that the "o1-preview (Post-Mitigation)" model performs best, followed closely by "o1 (Post-Mitigation)." The "o1 (Pre-Mitigation)" version performs worse than its post-mitigation counterpart. "GPT-4o" has the lowest accuracy of the four.
### Key Observations
* **Highest Performer:** `o1-preview (Post-Mitigation)` at 71%.
* **Lowest Performer:** `GPT-4o` at 59%.
* **Mitigation Impact:** For the `o1` model, the "Post-Mitigation" version (70%) shows a 4 percentage point improvement over the "Pre-Mitigation" version (66%).
* **Model Comparison:** Both `o1` variants (pre and post-mitigation) and the `o1-preview` variant outperform `GPT-4o` on this specific knowledge task.
* **Performance Cluster:** The three `o1`-family models cluster between 66% and 71%, while `GPT-4o` is a distinct outlier at a lower performance level.
### Interpretation
The data suggests that the `o1` model family, particularly in its post-mitigation states, demonstrates superior accuracy on this specialized benchmark for radiological and nuclear expert knowledge compared to `GPT-4o`. The term "mitigation" likely refers to a process applied to the model to reduce harmful outputs or biases, and the chart indicates this process did not degrade—and in the case of `o1` slightly improved—performance on this technical knowledge task.
The metric "Accuracy (cons @ 32)" is not defined in the chart, but "cons" could imply "consistency" or a specific evaluation protocol, and "@ 32" might refer to a parameter like the number of trials, a temperature setting, or a context length. The chart's primary message is a comparative performance ranking, highlighting the effectiveness of the `o1` models in this domain. The 12-percentage-point gap between the best (`o1-preview Post-Mitigation`) and worst (`GPT-4o`) performers is substantial, indicating significant differences in the models' training or capabilities regarding this expert knowledge.