## Bar Chart: Radiological and Nuclear Expert Knowledge
### Overview
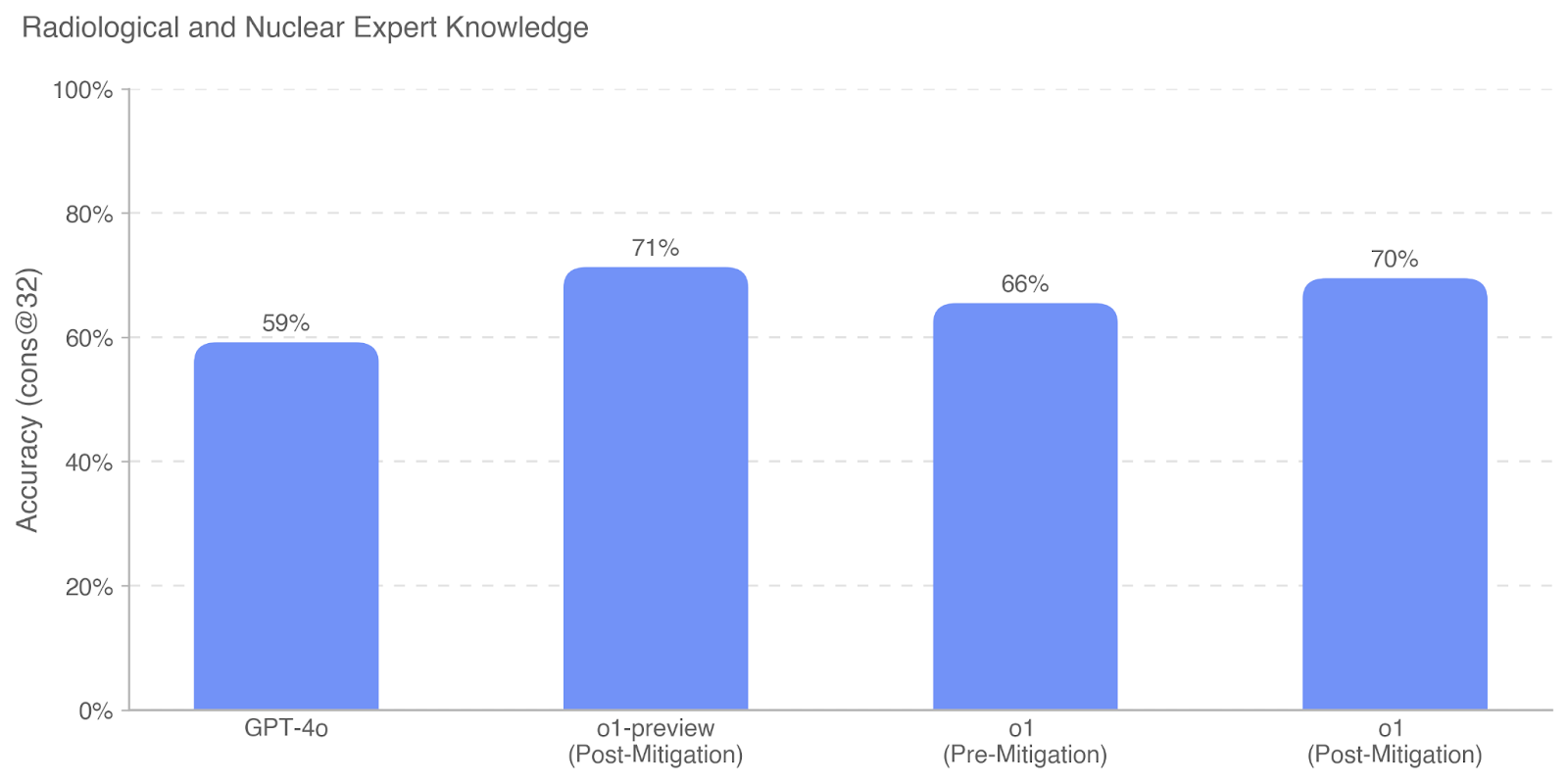
The chart compares the accuracy of radiological and nuclear expert knowledge across four model versions or mitigation states. Accuracy is measured in percentage (0–100%) on the y-axis, with four categories on the x-axis: GPT-4o, o1-preview (Post-Mitigation), o1 (Pre-Mitigation), and o1 (Post-Mitigation). All bars are colored blue.
### Components/Axes
- **X-Axis (Categories)**:
- GPT-4o
- o1-preview (Post-Mitigation)
- o1 (Pre-Mitigation)
- o1 (Post-Mitigation)
- **Y-Axis (Accuracy)**:
- Scaled from 0% to 100% in 20% increments.
- **Legend**: Not explicitly visible in the image. All bars use a uniform blue color, suggesting a single data series or unmarked categorical grouping.
- **Value Labels**: Percentages (59%, 71%, 66%, 70%) are displayed atop each bar.
### Detailed Analysis
1. **GPT-4o**: 59% accuracy, the lowest among the categories.
2. **o1-preview (Post-Mitigation)**: Highest accuracy at 71%.
3. **o1 (Pre-Mitigation)**: 66% accuracy, lower than its post-mitigation counterpart.
4. **o1 (Post-Mitigation)**: 70% accuracy, slightly below o1-preview but higher than pre-mitigation.
### Key Observations
- **Post-Mitigation Improvements**: Both o1-preview and o1 (Post-Mitigation) show higher accuracy than their pre-mitigation or baseline counterparts (GPT-4o and o1 Pre-Mitigation).
- **o1-preview Dominance**: Achieves the highest accuracy (71%), suggesting it may represent an optimized or advanced mitigation strategy.
- **o1 Pre-Mitigation Dip**: The 66% accuracy for o1 (Pre-Mitigation) is lower than its post-mitigation version (70%), indicating mitigation effectiveness.
- **GPT-4o Baseline**: Lags behind all other categories, potentially reflecting a less mature model or lack of mitigation.
### Interpretation
The data demonstrates that mitigation processes significantly enhance accuracy in radiological and nuclear expert knowledge models. The o1-preview (Post-Mitigation) achieves the highest performance, suggesting it may incorporate advanced mitigation techniques. The slight drop in accuracy for o1 (Post-Mitigation) compared to o1-preview could indicate trade-offs between mitigation scope and model performance. GPT-4o’s lower baseline accuracy highlights its potential as a starting point for further optimization. The consistent use of blue across all bars implies a unified evaluation framework, though the absence of a legend limits categorical differentiation. The trend underscores the value of iterative mitigation in improving model reliability for specialized domains.