\n
## Diagram: Data Transformation Pipeline
### Overview
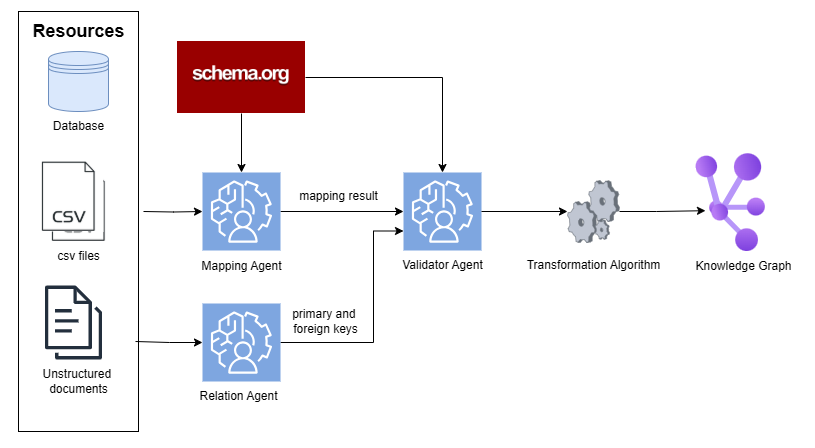
This diagram illustrates a data transformation pipeline that converts various data resources into a knowledge graph. The pipeline involves several agents and algorithms, starting with data sources and culminating in a structured knowledge representation.
### Components/Axes
The diagram consists of the following components:
* **Resources:** Represented by icons for a Database, CSV files, and Unstructured documents.
* **schema.org:** A red rectangle at the top, acting as a source of schema information.
* **Mapping Agent:** A light blue rounded rectangle with a human profile icon.
* **Validator Agent:** A light blue rounded rectangle with a human profile icon.
* **Relation Agent:** A light blue rounded rectangle with a human profile icon.
* **Transformation Algorithm:** A grey rounded rectangle with a gear icon.
* **Knowledge Graph:** A purple and blue cluster of nodes representing the final output.
* **Arrows:** Indicate the flow of data between components.
* **Labels:** "mapping result" and "primary and foreign keys" are labels on the arrows.
### Detailed Analysis or Content Details
The diagram shows a flow of data originating from three resource types:
1. **Database:** Data flows from the Database icon to the Mapping Agent.
2. **CSV files:** Data flows from the CSV files icon to the Mapping Agent.
3. **Unstructured documents:** Data flows from the Unstructured documents icon to the Relation Agent.
The Mapping Agent outputs "mapping result" to the Validator Agent. The Validator Agent then passes data to the Transformation Algorithm. The Relation Agent outputs "primary and foreign keys" to the Transformation Algorithm. The Transformation Algorithm then outputs to the Knowledge Graph.
schema.org provides input to both the Mapping Agent and the Validator Agent.
### Key Observations
The diagram highlights a multi-stage process for converting raw data into a structured knowledge graph. The use of separate agents for mapping, validation, and relation extraction suggests a modular and potentially parallelizable architecture. The inclusion of schema.org indicates the use of standardized vocabularies for data representation.
### Interpretation
This diagram depicts a typical Extract, Transform, Load (ETL) pipeline, specifically tailored for building a knowledge graph. The pipeline leverages schema.org to ensure semantic interoperability. The separation of relation extraction into a dedicated agent suggests a focus on identifying and representing relationships between entities within the data. The "mapping result" and "primary and foreign keys" labels indicate that the pipeline involves mapping data to a defined schema and identifying key relationships for graph construction. The final Knowledge Graph represents a structured and interconnected representation of the original data, enabling more sophisticated querying and analysis. The diagram suggests a system designed for integrating diverse data sources into a unified knowledge base.