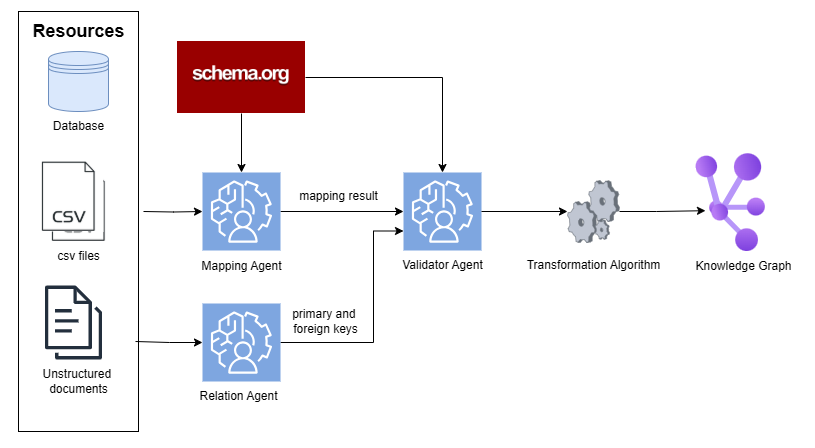
## Flowchart: Data Transformation Process
### Overview
The diagram illustrates a data transformation pipeline starting from raw resources (database, CSV files, unstructured documents) and ending with a structured Knowledge Graph. Key components include schema.org integration, mapping/validation agents, and a transformation algorithm.
### Components/Axes
1. **Resources** (Left Column):
- **Database** (icon: blue cylinder)
- **CSV files** (icon: document with "CSV" label)
- **Unstructured documents** (icon: document with lines)
2. **Schema.org** (Red box at top-center):
- Central schema reference
3. **Agents**:
- **Mapping Agent** (blue box with gear icon):
- Receives input from Resources
- Outputs "mapping result" to Validator Agent
- **Validator Agent** (blue box with gear icon):
- Receives "mapping result" from Mapping Agent
- Outputs "primary and foreign keys" to Relation Agent
- **Relation Agent** (blue box with gear icon):
- Receives "primary and foreign keys" from Validator Agent
4. **Transformation Algorithm** (Gears icon):
- Connects Validator Agent to Knowledge Graph
5. **Knowledge Graph** (Purple network of nodes):
- Final output of the pipeline
### Detailed Analysis
- **Flow Direction**:
- Resources → Schema.org → Mapping Agent → Validator Agent → Transformation Algorithm → Knowledge Graph
- Schema.org also directly connects to Validator Agent
- **Key Connections**:
- "mapping result" flows from Mapping Agent to Validator Agent
- "primary and foreign keys" flows from Validator Agent to Relation Agent
- **Color Coding**:
- Red: Schema.org (central authority)
- Blue: Agents (processing units)
- Purple: Knowledge Graph (structured output)
- Gray: Transformation Algorithm (mechanical process)
### Key Observations
1. Schema.org acts as a central schema reference influencing both Mapping and Validator Agents
2. Data undergoes sequential validation (Mapping → Validator → Relation Agents)
3. Transformation Algorithm bridges structured data (keys) to unstructured knowledge representation
4. No feedback loops or error-handling mechanisms depicted
### Interpretation
This diagram represents a knowledge graph construction pipeline where:
1. Raw data from multiple sources is first mapped to schema.org standards
2. Validation ensures data integrity through primary/foreign key relationships
3. Transformation Algorithm converts validated data into a semantic network (Knowledge Graph)
4. The absence of feedback loops suggests a linear, one-way data processing model
5. Schema.org's dual connections imply it serves both as input reference and validation checkpoint
The process emphasizes schema-driven data integration, with each agent specializing in specific transformation stages before reaching the final knowledge representation.