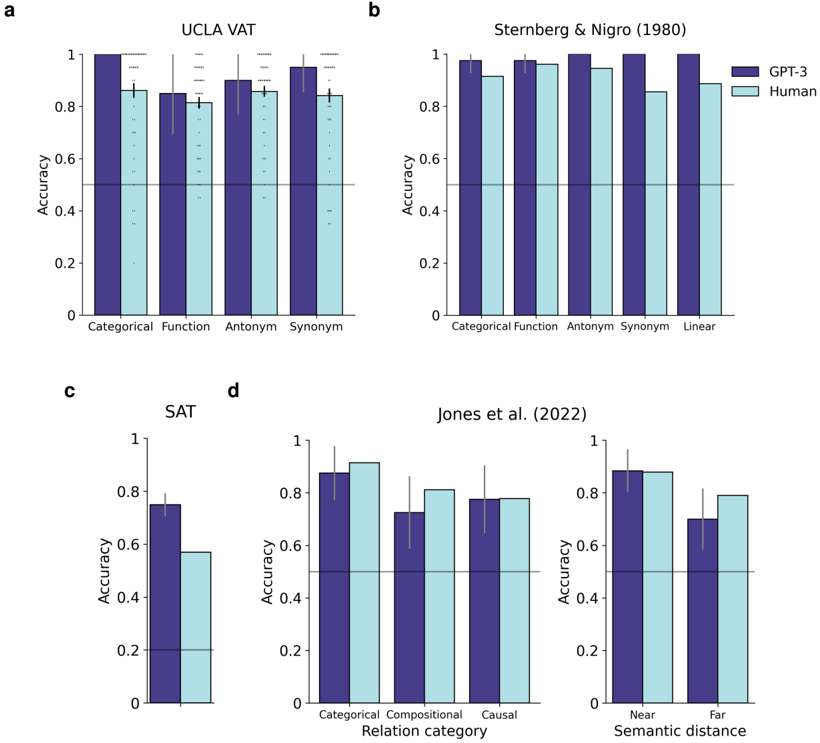
## Bar Charts: Accuracy Comparison of GPT-3 and Humans on Various Tasks
### Overview
The image presents four bar charts comparing the accuracy of GPT-3 and humans on different tasks: UCLA VAT, Sternberg & Nigro (1980), SAT, and Jones et al. (2022). Each chart displays accuracy scores for various categories within each task, with GPT-3 represented by dark blue bars and humans by light blue bars. Error bars are included on some bars, indicating variability in the data.
### Components/Axes
* **Y-axis (Accuracy):** All four charts share the same y-axis, labeled "Accuracy," ranging from 0 to 1 in increments of 0.2. A horizontal line is present at the 0.5 accuracy level on all charts.
* **X-axis:** Each chart has a different x-axis representing different categories or conditions within the specific task.
* **Legend:** Located in the top-right of the "Sternberg & Nigro (1980)" chart, the legend indicates that dark blue bars represent "GPT-3" and light blue bars represent "Human."
* **Chart Titles:** Each chart has a title indicating the task and, where applicable, the source of the data: "UCLA VAT," "Sternberg & Nigro (1980)," "SAT," and "Jones et al. (2022)."
### Detailed Analysis
**a) UCLA VAT**
* **Categories:** Categorical, Function, Antonym, Synonym
* **GPT-3 (Dark Blue):**
* Categorical: Accuracy approximately 0.98.
* Function: Accuracy approximately 0.83.
* Antonym: Accuracy approximately 0.90.
* Synonym: Accuracy approximately 0.83.
* **Human (Light Blue):**
* Categorical: Accuracy approximately 0.86.
* Function: Accuracy approximately 0.85.
* Antonym: Accuracy approximately 0.85.
* Synonym: Accuracy approximately 0.84.
* **Trend:** GPT-3 generally performs slightly better than humans across all categories, with the largest difference in the "Categorical" category.
**b) Sternberg & Nigro (1980)**
* **Categories:** Categorical, Function, Antonym, Synonym, Linear
* **GPT-3 (Dark Blue):**
* Categorical: Accuracy approximately 0.98.
* Function: Accuracy approximately 0.98.
* Antonym: Accuracy approximately 0.98.
* Synonym: Accuracy approximately 0.98.
* Linear: Accuracy approximately 1.0.
* **Human (Light Blue):**
* Categorical: Accuracy approximately 0.92.
* Function: Accuracy approximately 0.92.
* Antonym: Accuracy approximately 0.85.
* Synonym: Accuracy approximately 0.92.
* Linear: Accuracy approximately 0.85.
* **Trend:** GPT-3 consistently outperforms humans across all categories in this task.
**c) SAT**
* **Categories:** Only one category is shown.
* **GPT-3 (Dark Blue):** Accuracy approximately 0.75.
* **Human (Light Blue):** Accuracy approximately 0.57.
* **Trend:** GPT-3 performs better than humans on this SAT task.
**d) Jones et al. (2022)**
* **Categories:** Categorical, Compositional, Causal, Near, Far
* **GPT-3 (Dark Blue):**
* Categorical: Accuracy approximately 0.88.
* Compositional: Accuracy approximately 0.72.
* Causal: Accuracy approximately 0.78.
* Near: Accuracy approximately 0.88.
* Far: Accuracy approximately 0.70.
* **Human (Light Blue):**
* Categorical: Accuracy approximately 0.90.
* Compositional: Accuracy approximately 0.82.
* Causal: Accuracy approximately 0.78.
* Near: Accuracy approximately 0.82.
* Far: Accuracy approximately 0.78.
* **Trend:** The performance of GPT-3 and humans is relatively similar across these categories, with humans showing a slight advantage in "Compositional" and "Far" categories.
### Key Observations
* GPT-3 generally performs comparably to or better than humans on these tasks.
* The difference in performance varies depending on the specific task and category.
* Error bars indicate some variability in the data, particularly for the UCLA VAT and Jones et al. (2022) tasks.
### Interpretation
The data suggests that GPT-3 is capable of performing well on a variety of tasks that require understanding relationships between words and concepts. In some cases, such as the Sternberg & Nigro (1980) task, GPT-3 significantly outperforms humans. However, in other cases, such as the Jones et al. (2022) task, the performance is more comparable. This indicates that the relative strengths of GPT-3 and humans may depend on the specific demands of the task. The presence of error bars highlights the importance of considering the variability in the data when interpreting the results.