\n
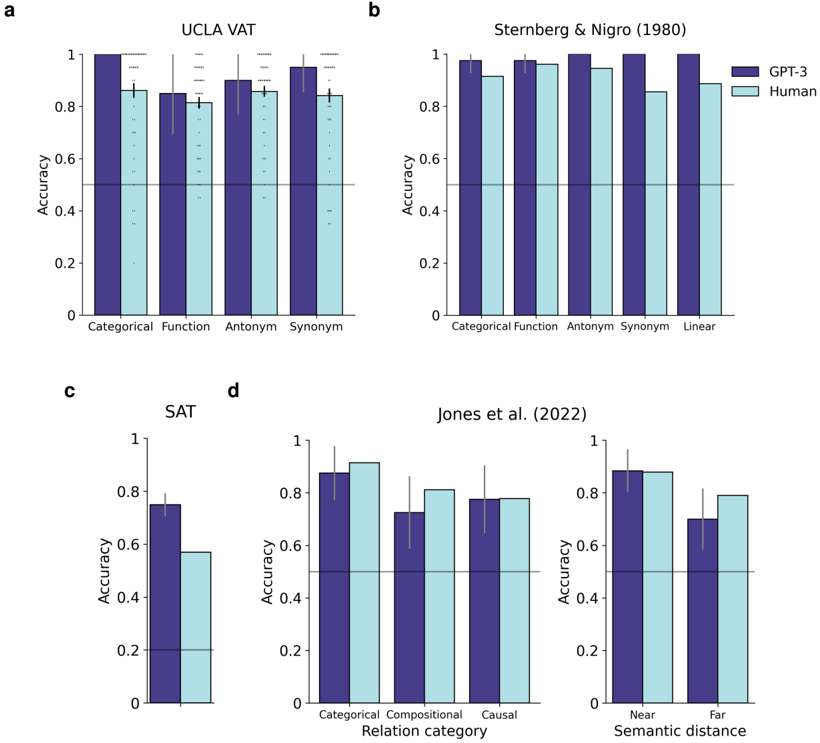
## Bar Charts: Accuracy of GPT-3 and Humans on Various Tasks
### Overview
The image presents four separate bar charts (labeled a, b, c, and d) comparing the accuracy of GPT-3 and human performance on different tasks related to semantic understanding and reasoning. Each chart focuses on a different dataset or task type. Error bars are present on each bar, indicating the variability in the data.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Represents the categories or conditions within the specific task.
* **Y-axis:** Represents "Accuracy," ranging from 0 to 1.
* **Bars:** Two bars per category, one representing GPT-3 performance (dark blue) and one representing human performance (light blue/grey).
* **Error Bars:** Vertical lines extending from each bar, indicating the standard error or confidence interval.
* **Titles:** Each chart has a title indicating the dataset or study used.
Specifics for each chart:
* **a: UCLA VAT:** Categories are "Categorical," "Function," "Antonym," and "Synonym."
* **b: Sternberg & Nigro (1980):** Categories are "Categorical," "Function," "Antonym," "Synonym," and "Linear."
* **c: SAT:** Categories are "Categorical," "Compositional," and "Causal."
* **d: Jones et al. (2022):** Categories are "Near" and "Far" Semantic distance.
### Detailed Analysis or Content Details
**a: UCLA VAT**
* **Categorical:** GPT-3 accuracy is approximately 0.88 (±0.02), Human accuracy is approximately 0.85 (±0.03).
* **Function:** GPT-3 accuracy is approximately 0.86 (±0.02), Human accuracy is approximately 0.83 (±0.03).
* **Antonym:** GPT-3 accuracy is approximately 0.87 (±0.02), Human accuracy is approximately 0.84 (±0.03).
* **Synonym:** GPT-3 accuracy is approximately 0.89 (±0.02), Human accuracy is approximately 0.86 (±0.03).
* Trend: GPT-3 consistently outperforms humans across all categories, with a slight advantage in the "Synonym" category.
**b: Sternberg & Nigro (1980)**
* **Categorical:** GPT-3 accuracy is approximately 0.91 (±0.01), Human accuracy is approximately 0.88 (±0.02).
* **Function:** GPT-3 accuracy is approximately 0.90 (±0.01), Human accuracy is approximately 0.87 (±0.02).
* **Antonym:** GPT-3 accuracy is approximately 0.90 (±0.01), Human accuracy is approximately 0.87 (±0.02).
* **Synonym:** GPT-3 accuracy is approximately 0.91 (±0.01), Human accuracy is approximately 0.88 (±0.02).
* **Linear:** GPT-3 accuracy is approximately 0.92 (±0.01), Human accuracy is approximately 0.89 (±0.02).
* Trend: GPT-3 consistently outperforms humans across all categories, with the largest advantage in the "Linear" category.
**c: SAT**
* **Categorical:** GPT-3 accuracy is approximately 0.88 (±0.02), Human accuracy is approximately 0.85 (±0.03).
* **Compositional:** GPT-3 accuracy is approximately 0.82 (±0.03), Human accuracy is approximately 0.78 (±0.04).
* **Causal:** GPT-3 accuracy is approximately 0.84 (±0.03), Human accuracy is approximately 0.80 (±0.04).
* Trend: GPT-3 consistently outperforms humans across all categories.
**d: Jones et al. (2022)**
* **Near:** GPT-3 accuracy is approximately 0.83 (±0.03), Human accuracy is approximately 0.78 (±0.04).
* **Far:** GPT-3 accuracy is approximately 0.79 (±0.03), Human accuracy is approximately 0.74 (±0.04).
* Trend: GPT-3 consistently outperforms humans, but the difference is smaller for "Far" semantic distance.
### Key Observations
* GPT-3 consistently outperforms humans across all tasks and categories.
* The performance gap between GPT-3 and humans appears to be larger for tasks involving more complex relationships (e.g., "Linear" in Sternberg & Nigro, "Compositional" and "Causal" in SAT).
* The difference in performance between GPT-3 and humans is smaller when semantic distance is "Far" (Jones et al.).
* Error bars suggest that the differences in performance are statistically significant in most cases.
### Interpretation
The data suggests that GPT-3 possesses a strong ability to understand and reason about semantic relationships, often exceeding human-level performance. This is particularly evident in tasks requiring the identification of complex relationships, such as linearity or causality. However, the performance gap narrows when dealing with more distant semantic relationships, indicating that GPT-3's understanding may be more sensitive to the proximity of concepts.
The consistent outperformance of GPT-3 across these diverse datasets highlights its potential as a powerful tool for natural language understanding and reasoning. The error bars provide a measure of confidence in these findings, suggesting that the observed differences are not simply due to chance. The varying performance gaps across different tasks suggest that the type of semantic relationship plays a crucial role in determining the relative strengths of GPT-3 and human performance. This could be due to differences in how humans and GPT-3 represent and process semantic information.