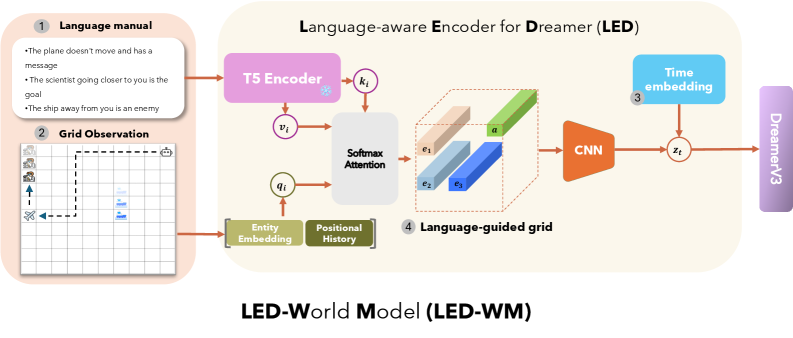
## Diagram: LED-World Model (LED-WM)
### Overview
The image is a diagram illustrating the architecture of the LED-World Model (LED-WM), which incorporates a Language-aware Encoder for Dreamer (LED). The diagram shows the flow of information from language manuals and grid observations through various components, including T5 Encoder, Softmax Attention, CNN, and Time embedding, ultimately feeding into DreamerV3.
### Components/Axes
* **Title:** LED-World Model (LED-WM)
* **Sub-title:** Language-aware Encoder for Dreamer (LED)
* **Numbered Components:**
1. Language manual
2. Grid Observation
3. Time embedding
4. Language-guided grid
* **Other Components:**
* T5 Encoder
* Softmax Attention
* CNN
* Entity Embedding
* Positional History
* DreamerV3
* **Variables:**
* k<sub>i</sub>
* v<sub>i</sub>
* q<sub>i</sub>
* z<sub>t</sub>
* a
* e<sub>1</sub>
* e<sub>2</sub>
* e<sub>3</sub>
### Detailed Analysis
1. **Language manual:**
* The plane doesn't move and has a message.
* The scientist going closer to you is the goal.
* The ship away from you is an enemy.
2. **Grid Observation:**
* A grid with several icons: buildings, a scientist, a ship, and an airplane.
* The airplane is moving to the left.
* The scientist is moving upwards.
* The ship is stationary.
3. **Time embedding:**
* A blue box labeled "Time embedding".
4. **Language-guided grid:**
* A 3D representation of the grid with elements labeled e1 (beige), e2 (light blue), e3 (dark blue), and 'a' (green).
* **T5 Encoder:** A pink box labeled "T5 Encoder". It receives input from the Language manual.
* **Softmax Attention:** A light gray box labeled "Softmax Attention". It receives input from T5 Encoder and Entity Embedding/Positional History.
* **CNN:** An orange trapezoid labeled "CNN". It receives input from the Language-guided grid.
* **Entity Embedding & Positional History:** A green box labeled "Entity Embedding" and "Positional History". It receives input from the Grid Observation.
* **DreamerV3:** A light purple box labeled "DreamerV3". It receives input from the combination of CNN and Time embedding.
### Key Observations
* The diagram illustrates a flow of information from language instructions and visual observations to a final output in DreamerV3.
* The Language-aware Encoder for Dreamer (LED) integrates language understanding with visual processing.
* The grid observation provides spatial information, while the language manual provides contextual information.
### Interpretation
The LED-World Model (LED-WM) architecture combines language understanding with visual perception to enable an agent (DreamerV3) to interact with a simulated environment. The language manual provides high-level instructions or goals, while the grid observation provides a detailed view of the environment. The T5 Encoder processes the language input, and the Entity Embedding/Positional History captures the spatial relationships within the grid. Softmax Attention mechanism likely focuses on relevant parts of the grid based on the language input. The CNN processes the language-guided grid, and the Time embedding adds temporal information. Finally, DreamerV3 uses this integrated information to make decisions and act in the environment. The model aims to create a more robust and intelligent agent by combining these different modalities of information.