\n
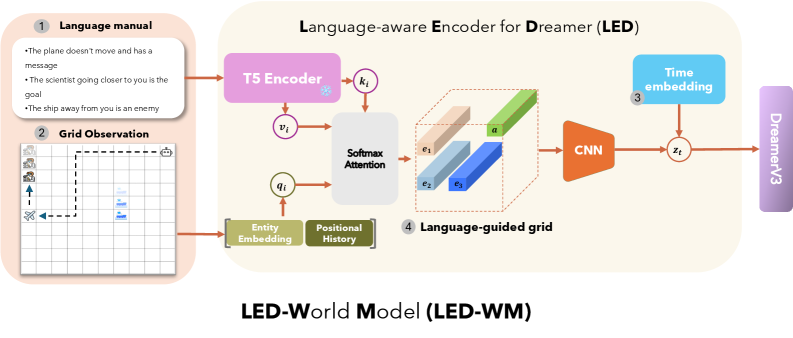
## Diagram: Language-aware Encoder for Dreamer (LED) - LED-World Model (LED-WM)
### Overview
This diagram illustrates the architecture of a Language-aware Encoder for Dreamer (LED), specifically within the context of an LED-World Model (LED-WM). The diagram depicts a data flow from a Language Manual and Grid Observation through several processing stages (T5 Encoder, Softmax Attention, CNN) to ultimately produce a state representation (z<sub>t</sub>) for Dreamer v3. The entire process is contained within a light gray box labeled "Language-aware Encoder for Dreamer (LED)".
### Components/Axes
The diagram consists of the following key components, numbered 1 through 4:
1. **Language manual:** Contains textual instructions.
2. **Grid Observation:** A grid-based visual representation.
3. **Time embedding:** A component that adds temporal information.
4. **Language-guided grid:** The output of the attention mechanism, visualized as a grid.
Additional components include:
* **T5 Encoder:** A text encoder.
* **Softmax Attention:** A mechanism for focusing on relevant parts of the input.
* **Entity Embedding:** A representation of entities within the language.
* **Positional History:** Information about the position of elements.
* **CNN:** A convolutional neural network.
* **Dreamer v3:** The ultimate recipient of the encoded state.
### Detailed Analysis or Content Details
Let's break down the data flow and components:
1. **Language Manual:** Contains the following text:
* "The plane doesn't move and has a message"
* "The scientist going closer to you is the goal"
* "The ship away from you is enemy"
2. **Grid Observation:** A 10x10 grid is shown. There are four visible objects:
* A blue square in the top-left corner.
* A blue square in the center.
* A blue square in the bottom-right corner.
* A white arrow pointing upwards.
3. **T5 Encoder:** Receives input 'v<sub>i</sub>' and outputs 'k<sub>i</sub>'. The T5 Encoder is a large language model.
4. **Softmax Attention:** Receives 'v<sub>i</sub>' and 'q<sub>i</sub>' as inputs. The output is a set of attention weights applied to the language-guided grid. The attention mechanism highlights four areas within the grid, labeled e<sub>1</sub>, e<sub>2</sub>, e<sub>3</sub>, and e<sub>4</sub>. These areas are represented as blue rectangular prisms.
5. **Entity Embedding & Positional History:** These are inputs to the Softmax Attention mechanism.
6. **CNN:** Receives the output of the Softmax Attention (the language-guided grid) and produces a state representation 'z<sub>t</sub>'.
7. **Time Embedding:** Provides temporal context to the state representation 'z<sub>t</sub>'.
8. **Dreamer v3:** Receives the final state representation 'z<sub>t</sub>'.
### Key Observations
* The diagram emphasizes the integration of language information with visual observations.
* The Softmax Attention mechanism appears to be crucial for aligning language instructions with the grid world.
* The CNN acts as a feature extractor, transforming the language-guided grid into a state representation suitable for Dreamer v3.
* The diagram is a high-level architectural overview and does not provide specific numerical values or parameters.
### Interpretation
The diagram illustrates a system designed to enable an agent (Dreamer v3) to learn and act in an environment based on both visual observations (Grid Observation) and natural language instructions (Language Manual). The Language-aware Encoder (LED) bridges the gap between these two modalities. The T5 Encoder processes the language, while the Softmax Attention mechanism focuses on relevant parts of the grid based on the language input. The CNN then extracts features from the language-guided grid, creating a state representation that captures both visual and linguistic information. This allows the agent to understand and execute commands expressed in natural language within a visual environment. The use of a T5 encoder suggests the system leverages pre-trained language models for improved performance. The overall architecture suggests a focus on interpretability and control, as the language input provides a clear signal for guiding the agent's behavior.