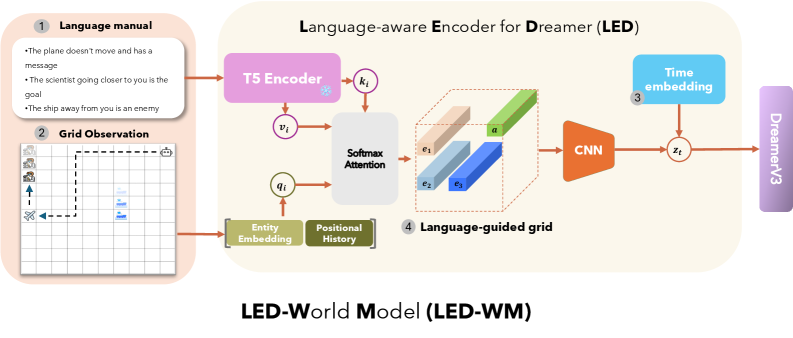
## Diagram: LED-World Model (LED-WM) Architecture
### Overview
This diagram illustrates the architecture of the LED-World Model (LED-WM), a language-aware encoder system for the Dreamer framework. It integrates natural language instructions, grid-based observations, and temporal embeddings to guide decision-making in a simulated environment. The model processes inputs through a T5 Encoder, attention mechanisms, and a CNN to produce a language-guided grid output for DreamerV3.
### Components/Axes
1. **Language Manual (Component 1)**
- Textual instructions:
- "The plane doesn't move and has a message"
- "The scientist going closer to you is the goal"
- "The ship away from you is an enemy"
2. **Grid Observation (Component 2)**
- Grid layout with symbols:
- Plane (✈️) at top-left
- Scientist (👨🔬) at bottom-left
- Ship (🚢) at bottom-right
- Dashed line path connecting entities
3. **Language-aware Encoder (LED) (Component 3)**
- **T5 Encoder**: Processes language manual inputs (`v_i`, `k_i`)
- **Softmax Attention**: Combines entity embeddings (`q_i`) with positional history
- **Entity Embedding**: Represents grid entities (plane, scientist, ship)
- **Positional History**: Tracks movement/relationships over time
- **Time Embedding**: Adds temporal context (`z_t`)
4. **Language-guided Grid (Component 4)**
- 3D grid with colored bars:
- `e1` (pink), `e2` (blue), `e3` (green)
- **CNN**: Processes grid data to extract features
5. **DreamerV3 (Component 5)**
- Final output module integrating temporal and spatial data
**Legend Colors**:
- Purple: T5 Encoder
- Green: Entity Embedding
- Blue: Positional History
- Orange: CNN
- Gray: Time Embedding
### Detailed Analysis
- **Language Manual**: Explicitly defines agent goals (scientist as goal, ship as enemy) and static entities (non-moving plane).
- **Grid Observation**: Visualizes spatial relationships between entities via dashed paths.
- **T5 Encoder**: Converts textual instructions into embeddings (`v_i`, `k_i`) for contextual understanding.
- **Softmax Attention**: Merges entity embeddings (`q_i`) with positional history to prioritize relevant grid regions.
- **CNN**: Extracts spatial features from the language-guided grid (`e1`, `e2`, `e3`).
- **Time Embedding**: Injects temporal context (`z_t`) to model dynamic interactions.
### Key Observations
- The model emphasizes **language grounding** by linking textual instructions (e.g., "scientist is the goal") to grid entities.
- **Attention mechanisms** dynamically weight grid regions based on linguistic and positional context.
- **CNN output** (`e1`, `e2`, `e3`) likely represents encoded spatial relationships for decision-making.
- **DreamerV3** integrates temporal (`z_t`) and spatial features to guide agent behavior.
### Interpretation
The LED-WM bridges natural language and grid-based perception by:
1. Translating instructions into embeddings via the T5 Encoder.
2. Using attention to focus on relevant grid regions (e.g., scientist as goal).
3. Combining spatial features (via CNN) with temporal context to inform DreamerV3's actions.
This architecture suggests a **multimodal reinforcement learning system** where language instructions directly shape agent navigation and goal-oriented behavior in a dynamic environment. The absence of numerical data implies the diagram focuses on architectural flow rather than quantitative performance metrics.