\n
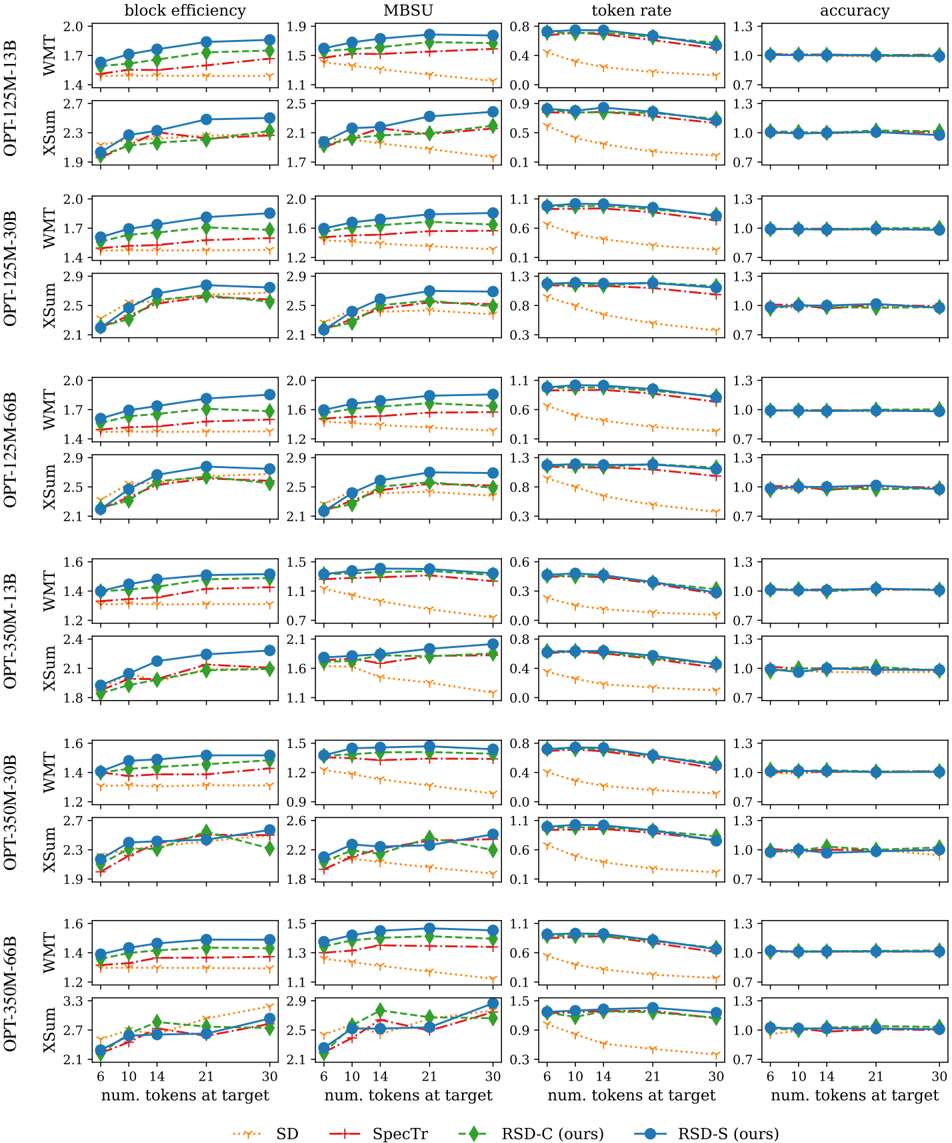
## Line Chart: Model Performance Metrics vs. Number of Layers
### Overview
The image presents a series of line charts comparing the performance of different language models (OPT-125M-1.3B, OPT-125M-3B, OPT-125M-6B, OPT-350M-1.3B, OPT-350M-30B, OPT-330M-60B) across four metrics: Block Efficiency, MBSU (Memory Bandwidth per Second Utilization), Token Rate, and Accuracy. The x-axis represents the number of layers (16, 32, 48, 64, 80, 96), and the y-axis scales vary for each metric. Each model is represented by three lines corresponding to different summation techniques: WMT, XSum, and XSum.
### Components/Axes
* **X-axis:** Number of Layers (16, 32, 48, 64, 80, 96)
* **Y-axes:**
* Block Efficiency: 1.2 to 2.0
* MBSU: 0.8 to 2.9
* Token Rate: 0.0 to 1.3
* Accuracy: 0.6 to 1.3
* **Models (Rows):**
* OPT-125M-1.3B
* OPT-125M-3B
* OPT-125M-6B
* OPT-350M-1.3B
* OPT-350M-30B
* OPT-330M-60B
* **Summation Techniques (Lines within each model):**
* WMT (Solid Line) - Color: Red
* XSum (Dashed Line) - Color: Green
* XSum (Dotted Line) - Color: Blue
* **Legend:** Located in the top-right corner, mapping colors to metrics.
### Detailed Analysis or Content Details
Here's a breakdown of the trends and approximate values for each metric and model. Note that values are estimated from the chart.
**OPT-125M-1.3B:**
* **Block Efficiency:** All three lines start around 1.4 and generally increase to around 1.7-1.8 by 96 layers. WMT shows a slight increase, XSum (dashed) is relatively flat, and XSum (dotted) shows a moderate increase.
* **MBSU:** Starts around 1.1 for all lines. WMT increases to ~1.5, XSum (dashed) to ~1.2, and XSum (dotted) to ~2.1 by 96 layers.
* **Token Rate:** Starts around 0.4 for all lines. WMT remains relatively flat around 0.4-0.5, XSum (dashed) increases to ~0.6, and XSum (dotted) increases to ~0.9 by 96 layers.
* **Accuracy:** All lines start around 0.7. WMT remains around 0.7, XSum (dashed) increases to ~0.8, and XSum (dotted) increases to ~1.0 by 96 layers.
**OPT-125M-3B:**
* **Block Efficiency:** Similar to 1.3B, lines start around 1.6 and increase to 1.7-1.9.
* **MBSU:** Starts around 1.2. WMT increases to ~1.9, XSum (dashed) to ~1.4, and XSum (dotted) to ~2.5 by 96 layers.
* **Token Rate:** Starts around 0.4. WMT remains flat, XSum (dashed) increases to ~0.6, and XSum (dotted) increases to ~1.1 by 96 layers.
* **Accuracy:** All lines start around 0.7. WMT remains around 0.7, XSum (dashed) increases to ~0.8, and XSum (dotted) increases to ~1.1 by 96 layers.
**OPT-125M-6B:**
* **Block Efficiency:** Starts around 1.4 and increases to 1.7-1.9.
* **MBSU:** Starts around 1.1. WMT increases to ~2.1, XSum (dashed) to ~1.6, and XSum (dotted) to ~2.5 by 96 layers.
* **Token Rate:** Starts around 0.4. WMT remains flat, XSum (dashed) increases to ~0.6, and XSum (dotted) increases to ~0.9 by 96 layers.
* **Accuracy:** All lines start around 0.7. WMT remains around 0.7, XSum (dashed) increases to ~0.8, and XSum (dotted) increases to ~1.1 by 96 layers.
**OPT-350M-1.3B:**
* **Block Efficiency:** Starts around 1.2 and increases to 1.4-1.6.
* **MBSU:** Starts around 0.9. WMT increases to ~1.7, XSum (dashed) to ~1.2, and XSum (dotted) to ~2.1 by 96 layers.
* **Token Rate:** Starts around 0.3. WMT remains flat, XSum (dashed) increases to ~0.6, and XSum (dotted) increases to ~1.0 by 96 layers.
* **Accuracy:** All lines start around 0.7. WMT remains around 0.7, XSum (dashed) increases to ~0.8, and XSum (dotted) increases to ~1.1 by 96 layers.
**OPT-350M-30B:**
* **Block Efficiency:** Starts around 1.2 and increases to 1.4-1.6.
* **MBSU:** Starts around 0.9. WMT increases to ~1.7, XSum (dashed) to ~1.2, and XSum (dotted) to ~2.1 by 96 layers.
* **Token Rate:** Starts around 0.3. WMT remains flat, XSum (dashed) increases to ~0.6, and XSum (dotted) increases to ~1.0 by 96 layers.
* **Accuracy:** All lines start around 0.7. WMT remains around 0.7, XSum (dashed) increases to ~0.8, and XSum (dotted) increases to ~1.1 by 96 layers.
**OPT-330M-60B:**
* **Block Efficiency:** Starts around 1.3 and increases to 1.5-1.7.
* **MBSU:** Starts around 1.0. WMT increases to ~1.9, XSum (dashed) to ~1.4, and XSum (dotted) to ~2.3 by 96 layers.
* **Token Rate:** Starts around 0.3. WMT remains flat, XSum (dashed) increases to ~0.6, and XSum (dotted) increases to ~1.0 by 96 layers.
* **Accuracy:** All lines start around 0.7. WMT remains around 0.7, XSum (dashed) increases to ~0.8, and XSum (dotted) increases to ~1.1 by 96 layers.
### Key Observations
* Generally, increasing the number of layers improves MBSU, Token Rate, and Accuracy, but the improvement plateaus after 64-80 layers for most models.
* The XSum (dotted) summation technique consistently outperforms WMT and XSum (dashed) across all metrics.
* Larger models (OPT-330M-60B) generally exhibit higher MBSU and Accuracy compared to smaller models (OPT-125M-1.3B).
* Block Efficiency shows relatively small changes across different models and summation techniques.
* WMT summation technique shows the least improvement with increasing layers.
### Interpretation
The data suggests that increasing model size and the number of layers generally improves performance, particularly in terms of memory bandwidth utilization (MBSU), token rate, and accuracy. The XSum (dotted) summation technique appears to be the most effective at leveraging increased model capacity. The plateauing of performance after a certain number of layers indicates diminishing returns, suggesting that further increasing model size beyond a certain point may not yield significant improvements. The consistent underperformance of the WMT summation technique suggests it may be less efficient at utilizing the available computational resources. This data is valuable for optimizing model architecture and training strategies to achieve the best possible performance for a given computational budget. The consistent trend across all models suggests a general principle about scaling language models, but further investigation is needed to understand the specific reasons behind these observations.