TECHNICAL ASSET FINGERPRINT
ce89f4cb7e16a2da5f1d6ca4
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
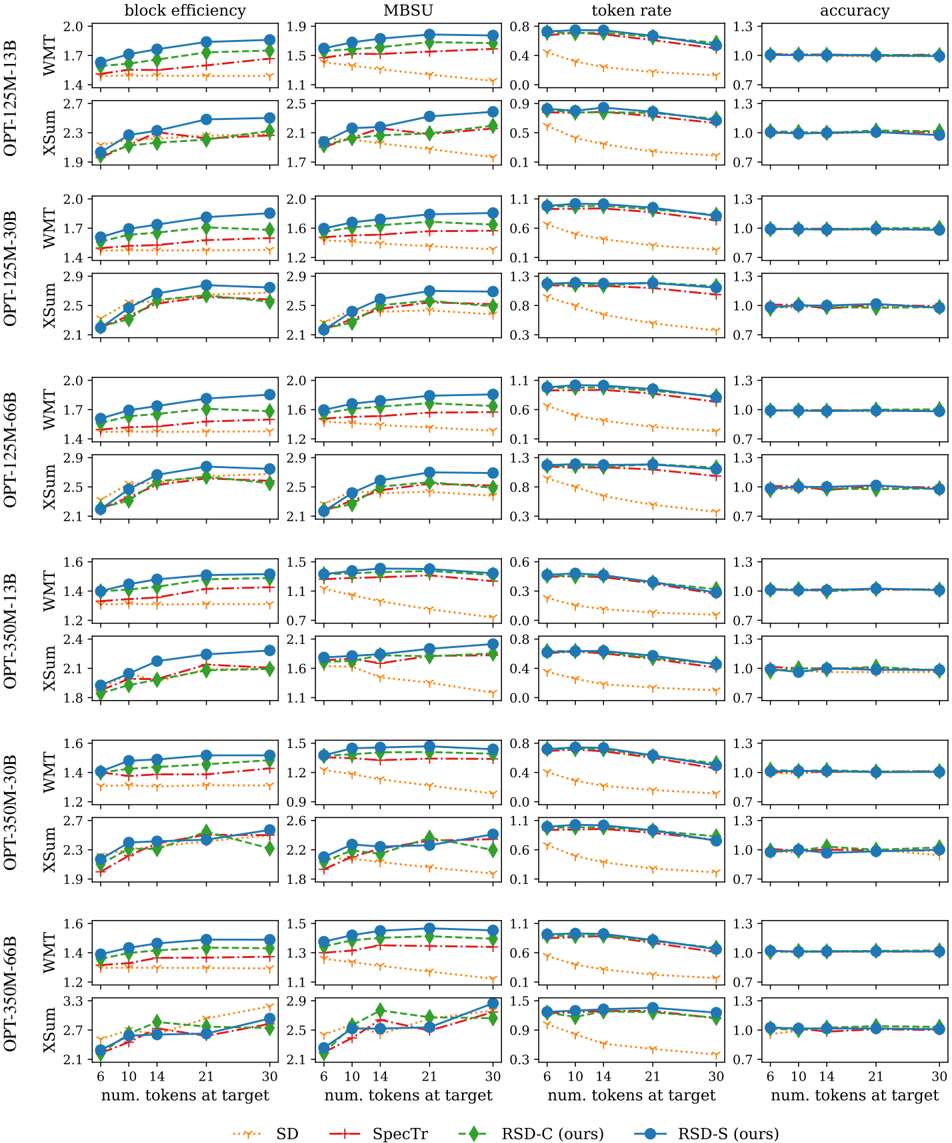
## Line Chart Grid: Performance Comparison of Speculative Decoding Methods
### Overview
The image displays a grid of 24 line charts comparing the performance of four speculative decoding methods across two model families (OPT-125M and OPT-350M), two model sizes each (13B, 30B, 66B), and two datasets (WMT, XSum). The comparison is made across four metrics: block efficiency, MBSU, token rate, and accuracy. The x-axis for all charts is the number of tokens at the target model.
### Components/Axes
* **Grid Structure:** 12 rows x 4 columns.
* **Rows:** Grouped by model family, model size, and dataset.
* Row 1: OPT-125M-13B, WMT
* Row 2: OPT-125M-13B, XSum
* Row 3: OPT-125M-30B, WMT
* Row 4: OPT-125M-30B, XSum
* Row 5: OPT-125M-66B, WMT
* Row 6: OPT-125M-66B, XSum
* Row 7: OPT-350M-13B, WMT
* Row 8: OPT-350M-13B, XSum
* Row 9: OPT-350M-30B, WMT
* Row 10: OPT-350M-30B, XSum
* Row 11: OPT-350M-66B, WMT
* Row 12: OPT-350M-66B, XSum
* **Columns:** Represent performance metrics.
* Column 1: `block efficiency`
* Column 2: `MBSU`
* Column 3: `token rate`
* Column 4: `accuracy`
* **X-Axis (All Charts):** `num. tokens at target`. Ticks at values: 6, 10, 14, 21, 30.
* **Y-Axis:** Varies by metric column. Approximate ranges:
* `block efficiency`: ~1.2 to 3.3
* `MBSU`: ~0.7 to 2.9
* `token rate`: ~0.1 to 1.5
* `accuracy`: ~0.7 to 1.3 (centered around 1.0)
* **Legend (Bottom Center):**
* `SD`: Orange dotted line with 'x' markers.
* `SpecTr`: Red dash-dot line with '+' markers.
* `RSD-C (ours)`: Green dashed line with diamond markers.
* `RSD-S (ours)`: Blue solid line with circle markers.
### Detailed Analysis
**1. Block Efficiency (Column 1):**
* **Trend:** For all methods, block efficiency generally increases as the number of target tokens increases.
* **Performance Order (Highest to Lowest):** RSD-S (blue) > RSD-C (green) > SpecTr (red) > SD (orange). This order is consistent across all model sizes and datasets.
* **Approximate Values (Example: OPT-125M-13B, WMT):**
* At 6 tokens: SD ~1.4, SpecTr ~1.5, RSD-C ~1.6, RSD-S ~1.7.
* At 30 tokens: SD ~1.5, SpecTr ~1.6, RSD-C ~1.8, RSD-S ~1.9.
* **Notable:** The gap between RSD methods and the baselines (SD, SpecTr) is significant and widens slightly with more tokens. The XSum dataset shows higher absolute values than WMT for the same models.
**2. MBSU (Column 2):**
* **Trend:** Similar upward trend as block efficiency. MBSU increases with more target tokens.
* **Performance Order:** Consistently RSD-S > RSD-C > SpecTr > SD.
* **Approximate Values (Example: OPT-350M-30B, XSum):**
* At 6 tokens: SD ~1.1, SpecTr ~1.5, RSD-C ~1.6, RSD-S ~1.7.
* At 30 tokens: SD ~1.2, SpecTr ~1.8, RSD-C ~2.2, RSD-S ~2.3.
* **Notable:** The RSD methods show a steeper improvement slope compared to SD and SpecTr, especially on the XSum dataset.
**3. Token Rate (Column 3):**
* **Trend:** For all methods, the token rate **decreases** as the number of target tokens increases. This is an inverse relationship compared to the other metrics.
* **Performance Order:** RSD-S and RSD-C are very close and consistently higher than SpecTr, which is higher than SD.
* **Approximate Values (Example: OPT-125M-66B, WMT):**
* At 6 tokens: SD ~0.5, SpecTr ~0.9, RSD-C ~1.0, RSD-S ~1.0.
* At 30 tokens: SD ~0.2, SpecTr ~0.7, RSD-C ~0.8, RSD-S ~0.8.
* **Notable:** The decline is most pronounced for the SD method. The RSD methods maintain a higher token rate throughout, indicating better efficiency in generating accepted tokens.
**4. Accuracy (Column 4):**
* **Trend:** Accuracy is remarkably stable and close to 1.0 for all methods across all token counts. There is very little variation.
* **Performance Order:** All methods perform nearly identically, with lines overlapping at the 1.0 mark.
* **Approximate Values:** All data points cluster tightly around 1.0 (range ~0.95 to 1.05).
* **Notable:** This indicates that the speculative decoding methods, including the proposed RSD variants, do not compromise the final output accuracy of the target model compared to standard decoding (implied baseline of 1.0).
### Key Observations
1. **Consistent Superiority:** The proposed methods, RSD-S and RSD-C, consistently outperform the baselines (SD and SpecTr) across the primary efficiency metrics (block efficiency, MBSU, token rate) for every model size and dataset combination.
2. **Metric Correlation:** Block efficiency and MBSU show very similar trends and rankings, suggesting they capture related aspects of speculative decoding performance.
3. **Token Rate Trade-off:** While block efficiency improves with more target tokens, the token rate declines. This highlights a fundamental trade-off: attempting to draft more tokens at once increases the chance of accepting a larger block (higher efficiency) but reduces the rate at which tokens are generated per unit of computation.
4. **Accuracy Preservation:** All methods maintain near-perfect accuracy (~1.0), confirming that speed improvements do not come at the cost of output quality.
5. **Scalability:** The performance advantage of RSD methods is maintained as the target model size increases from 13B to 66B, suggesting good scalability.
6. **Dataset Effect:** The XSum dataset generally yields higher absolute values for block efficiency and MBSU compared to WMT for the same model, indicating that the effectiveness of speculative decoding can be task-dependent.
### Interpretation
The data demonstrates that the authors' proposed methods, **RSD-S and RSD-C, provide a significant and consistent improvement in speculative decoding efficiency** over the existing SD and SpecTr methods. They achieve higher block efficiencies and MBSU scores, meaning they successfully draft and verify longer sequences of tokens in each step. Crucially, they do this while maintaining a higher token generation rate and without any degradation in final model accuracy.
The inverse trend in token rate versus block efficiency reveals an optimization landscape: there is an optimal number of tokens to draft that balances the probability of accepting a large block against the computational cost of verifying a long, potentially incorrect sequence. The RSD methods appear to navigate this trade-off more effectively.
The consistent results across different model scales (13B to 66B) and tasks (WMT translation, XSum summarization) suggest that the RSD approach is robust and generalizable. The fact that accuracy remains at ~1.0 for all methods is a critical validation, ensuring that the pursuit of speed does not undermine the model's core functionality. In summary, the charts present strong evidence that the RSD techniques advance the state-of-the-art in making large language model inference faster without sacrificing quality.
DECODING INTELLIGENCE...