## Bar Chart: Token Generation Speed Comparison
### Overview
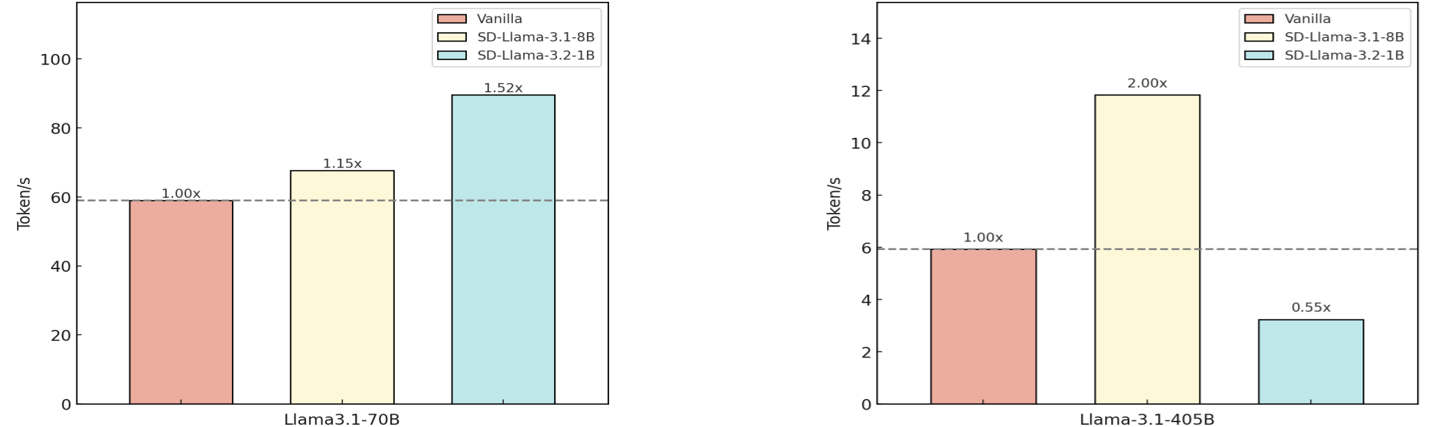
The image presents two bar charts comparing the token generation speed (tokens/s) of different model configurations: "Vanilla", "SD-Llama-3.1-8B", and "SD-Llama-3.2-1B". The left chart compares these configurations for "Llama3.1-70B", while the right chart compares them for "Llama-3.1-405B". The charts also display the relative speed compared to the "Vanilla" configuration, indicated by values like "1.00x", "1.15x", "1.52x", "2.00x", and "0.55x".
### Components/Axes
**Left Chart:**
* **X-axis:** "Llama3.1-70B"
* **Y-axis:** "Token/s", ranging from 0 to 100, with tick marks at intervals of 20.
* **Legend (Top-Right):**
* Vanilla (light red)
* SD-Llama-3.1-8B (light yellow)
* SD-Llama-3.2-1B (light blue)
**Right Chart:**
* **X-axis:** "Llama-3.1-405B"
* **Y-axis:** "Token/s", ranging from 0 to 14, with tick marks at intervals of 2.
* **Legend (Top-Right):**
* Vanilla (light red)
* SD-Llama-3.1-8B (light yellow)
* SD-Llama-3.2-1B (light blue)
**Shared Elements:**
* A horizontal dashed line is present on both charts, representing the "Vanilla" model's token/s value.
* The relative speed compared to the "Vanilla" configuration is displayed above each bar.
### Detailed Analysis
**Left Chart (Llama3.1-70B):**
* **Vanilla (light red):** The bar reaches approximately 60 tokens/s. The relative speed is labeled as "1.00x".
* **SD-Llama-3.1-8B (light yellow):** The bar reaches approximately 69 tokens/s. The relative speed is labeled as "1.15x".
* **SD-Llama-3.2-1B (light blue):** The bar reaches approximately 91 tokens/s. The relative speed is labeled as "1.52x".
**Right Chart (Llama-3.1-405B):**
* **Vanilla (light red):** The bar reaches approximately 6 tokens/s. The relative speed is labeled as "1.00x".
* **SD-Llama-3.1-8B (light yellow):** The bar reaches approximately 12 tokens/s. The relative speed is labeled as "2.00x".
* **SD-Llama-3.2-1B (light blue):** The bar reaches approximately 3.3 tokens/s. The relative speed is labeled as "0.55x".
### Key Observations
* For the Llama3.1-70B model, both SD-Llama configurations outperform the Vanilla model in terms of token generation speed. SD-Llama-3.2-1B shows the most significant improvement.
* For the Llama-3.1-405B model, SD-Llama-3.1-8B significantly outperforms the Vanilla model, while SD-Llama-3.2-1B performs worse.
### Interpretation
The charts demonstrate the impact of different model configurations on token generation speed. The results vary depending on the base model (Llama3.1-70B vs. Llama-3.1-405B). For Llama3.1-70B, both SD-Llama configurations improve performance. However, for Llama-3.1-405B, SD-Llama-3.1-8B provides a substantial performance boost, while SD-Llama-3.2-1B reduces performance. This suggests that the effectiveness of these configurations is model-dependent, and careful consideration is needed when choosing a configuration for a specific model. The "Vanilla" model serves as a baseline for comparison, allowing for easy assessment of the relative performance gains or losses associated with the SD-Llama configurations.