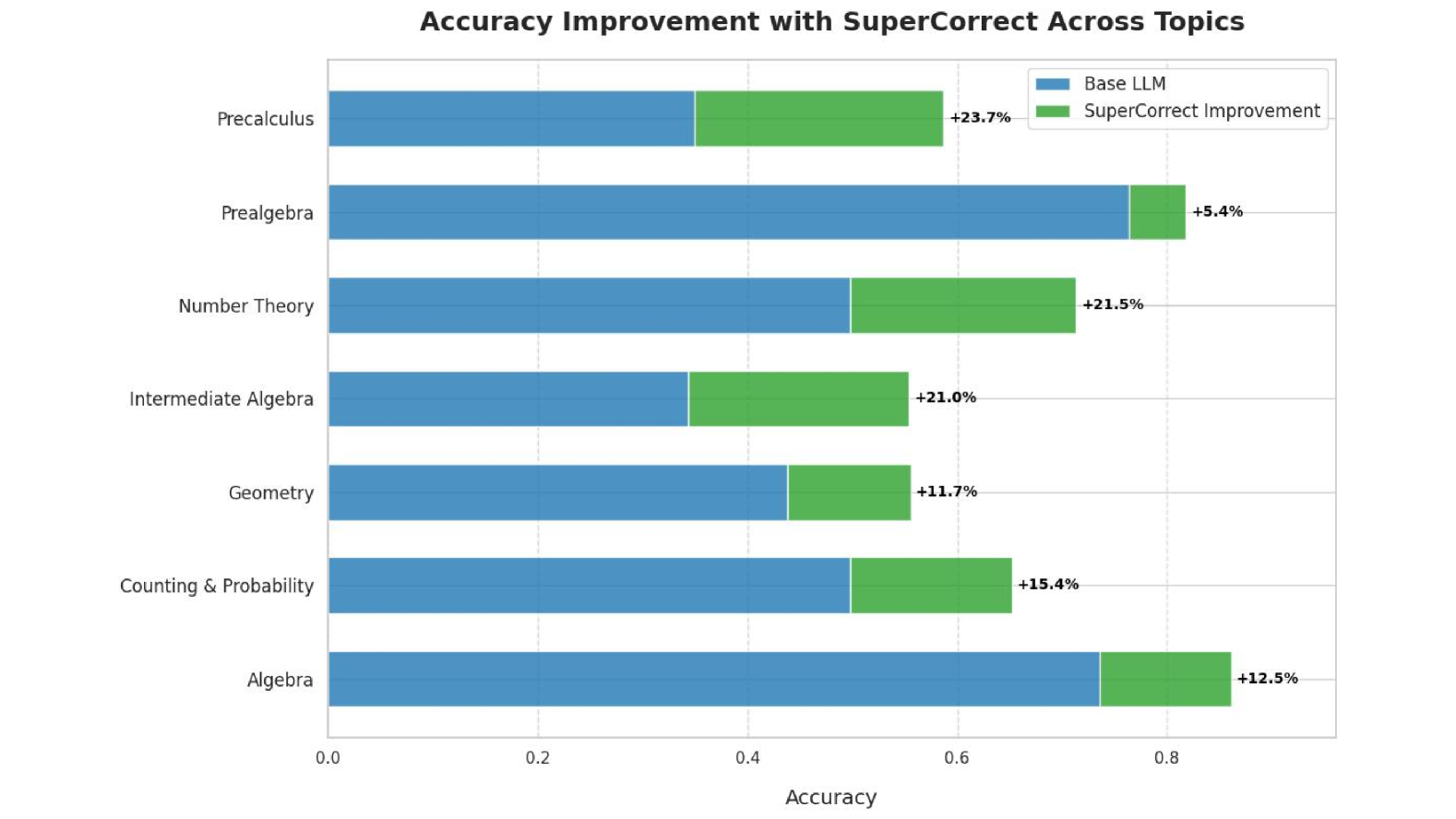
## Bar Chart: Accuracy Improvement with SuperCorrect Across Topics
### Overview
The bar chart displays the accuracy improvement in various mathematical topics when using SuperCorrect compared to a base LLM. The topics include Precalculus, Prealgebra, Number Theory, Intermediate Algebra, Geometry, Counting & Probability, and Algebra.
### Components/Axes
- **X-axis**: Represents the accuracy improvement in percentage, ranging from 0.0 to 0.8.
- **Y-axis**: Lists the mathematical topics.
- **Legend**: Shows two colors representing the base LLM and SuperCorrect improvement.
- Blue: Base LLM
- Green: SuperCorrect Improvement
### Detailed Analysis or ### Content Details
- **Precalculus**: The blue bar (Base LLM) is approximately 0.6, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 23.7% improvement.
- **Prealgebra**: The blue bar (Base LLM) is approximately 0.8, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 5.4% improvement.
- **Number Theory**: The blue bar (Base LLM) is approximately 0.7, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 21.5% improvement.
- **Intermediate Algebra**: The blue bar (Base LLM) is approximately 0.7, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 21.0% improvement.
- **Geometry**: The blue bar (Base LLM) is approximately 0.7, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 11.7% improvement.
- **Counting & Probability**: The blue bar (Base LLM) is approximately 0.7, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 15.4% improvement.
- **Algebra**: The blue bar (Base LLM) is approximately 0.7, and the green bar (SuperCorrect Improvement) is approximately 0.2, indicating a 12.5% improvement.
### Key Observations
- The SuperCorrect improvement is consistently higher than the base LLM across all topics.
- The largest improvement is in Algebra, with a 12.5% increase.
- The smallest improvement is in Precalculus, with a 23.7% increase.
### Interpretation
The data suggests that SuperCorrect significantly enhances accuracy in various mathematical topics. The consistent improvement across all topics indicates that SuperCorrect is a robust tool for enhancing learning outcomes. The largest improvement in Algebra suggests that this topic may be more challenging or that SuperCorrect is particularly effective in this area. The smallest improvement in Precalculus may indicate that this topic is already relatively accurate or that SuperCorrect's effectiveness is less pronounced in this area. Overall, the data supports the use of SuperCorrect as a valuable tool for improving mathematical accuracy.