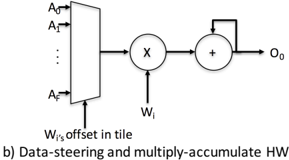
## Diagram: Data-steering and multiply-accumulate HW
### Overview
The diagram illustrates a hardware architecture for a multiply-accumulate (MAC) unit with data-steering capabilities. It shows the flow of data from multiple input sources (A₀ to A_F) through a processing pipeline involving a multiplier-accumulator (MAC) unit, with an offset mechanism and feedback loop.
### Components/Axes
1. **Input Block**:
- Labeled with inputs A₀ (top) to A_F (bottom), arranged vertically.
- Represents multiple data sources feeding into the system.
2. **Multiplier-Accumulator (MAC) Unit**:
- Central component labeled "X" (multiplier) and "+" (accumulator).
- Connected to input block via a horizontal arrow.
3. **Offset Mechanism**:
- Labeled "W_i's offset in tile" below the input block.
- Suggests adjustable weighting or positional adjustment for inputs.
4. **Feedback Loop**:
- Output O₀ (rightmost output) feeds back into the MAC unit via a looped arrow.
5. **Output**:
- Final output labeled O₀, exiting the system after MAC processing.
### Detailed Analysis
- **Data Flow**:
- Inputs A₀–A_F are processed sequentially or in parallel (not explicitly shown) into the MAC unit.
- The MAC unit multiplies inputs by weights (W_i) and accumulates results.
- The offset mechanism adjusts input values before multiplication, likely for precision or alignment.
- Feedback from O₀ suggests iterative processing (e.g., recurrent operations or pipelining).
- **Key Connections**:
- Input block → MAC unit (direct path).
- MAC unit → Output O₀ (primary path).
- O₀ → MAC unit (feedback path).
### Key Observations
- The architecture emphasizes **parallel input handling** (A₀–A_F) and **sequential MAC operations**.
- The offset mechanism implies **adaptive weighting** or **tile-based processing** (common in matrix operations or neural networks).
- Feedback loop indicates **recurrent computation** or **loop unrolling** for efficiency.
### Interpretation
This diagram represents a **data-steering MAC unit** optimized for high-throughput, parallelizable workloads (e.g., AI/ML inference, signal processing). The offset mechanism allows dynamic adjustment of input values, critical for precision in fixed-point arithmetic. The feedback loop enables **recurrent operations** (e.g., convolutional layers) without requiring additional memory bandwidth. The design prioritizes **throughput** and **energy efficiency** by minimizing data movement between stages. The absence of explicit control logic suggests this is a simplified block diagram focusing on data flow rather than timing or synchronization.