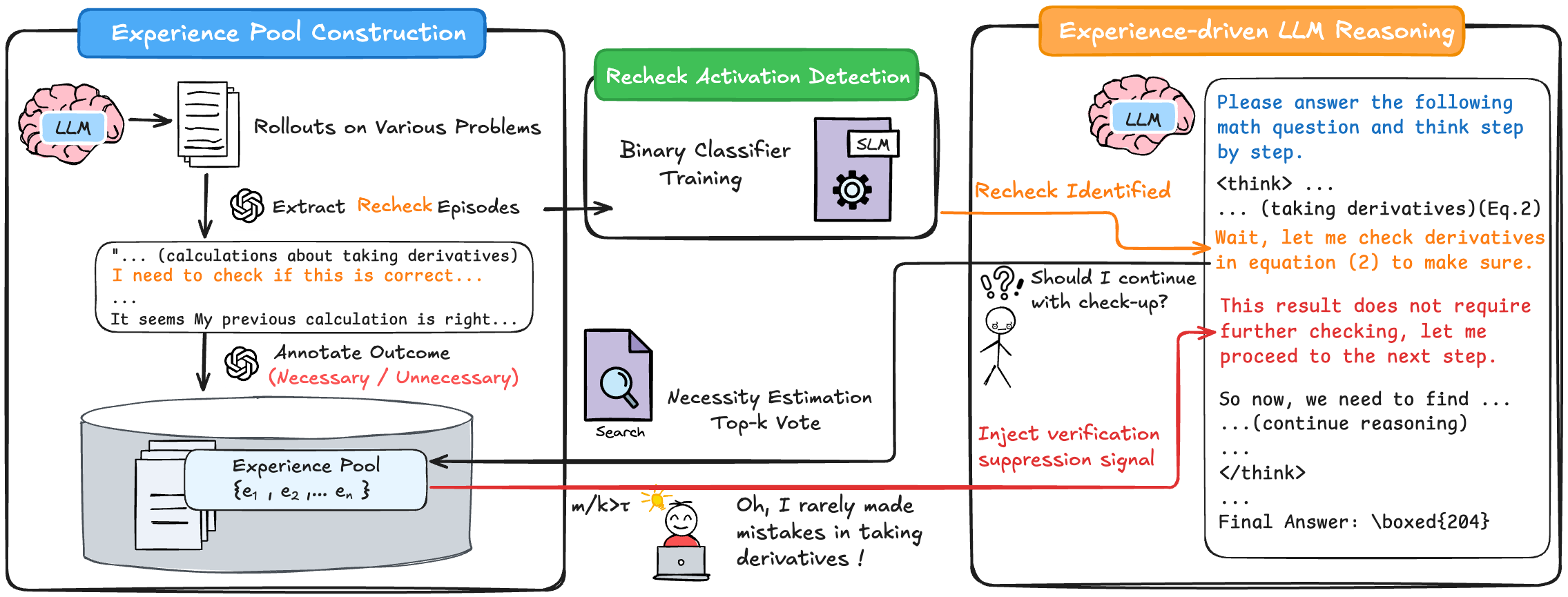
## Diagram: Experience-driven LLM Reasoning
### Overview
The image is a diagram illustrating the process of experience-driven LLM reasoning, broken down into three main stages: Experience Pool Construction, Recheck Activation Detection, and Experience-driven LLM Reasoning. It shows how an LLM uses past experiences to improve its reasoning process, particularly in mathematical problem-solving.
### Components/Axes
* **Header Regions:**
* Top-left: "Experience Pool Construction" (blue box)
* Top-center: "Recheck Activation Detection" (green box)
* Top-right: "Experience-driven LLM Reasoning" (orange box)
* **Components:**
* **Experience Pool Construction:**
* LLM (brain icon with "LLM" label)
* "Rollouts on Various Problems" (represented by a stack of papers)
* "Extract Recheck Episodes" (represented by a circular arrow icon)
* Text bubble: "... (calculations about taking derivatives) I need to check if this is correct... It seems My previous calculation is right..."
* "Annotate Outcome (Necessary / Unnecessary)" (represented by a circular arrow icon)
* "Experience Pool {e1, e2, ..., en}" (represented by a database icon)
* **Recheck Activation Detection:**
* "Binary Classifier Training"
* SLM (represented by a gear icon inside a document)
* "Necessity Estimation Top-k Vote"
* "Search" (represented by a document with a magnifying glass)
* A stick figure with a thought bubble: "Should I continue with check-up?"
* Text: "m/k > τ"
* A person sitting at a computer: "Oh, I rarely made mistakes in taking derivatives!"
* **Experience-driven LLM Reasoning:**
* LLM (brain icon with "LLM" label)
* Text bubble: "Please answer the following math question and think step by step. ... (taking derivatives)(Eq.2) Wait, let me check derivatives in equation (2) to make sure. This result does not require further checking, let me proceed to the next step. So now, we need to find ... (continue reasoning) Final Answer: \boxed{204}"
* "Recheck Identified"
* "Inject verification suppression signal"
### Detailed Analysis or Content Details
1. **Experience Pool Construction:**
* An LLM performs rollouts on various problems.
* Recheck episodes are extracted from these rollouts.
* The outcomes are annotated as either necessary or unnecessary.
* This information is stored in an experience pool.
2. **Recheck Activation Detection:**
* A binary classifier is trained, potentially using an SLM (Statistical Language Model).
* Necessity estimation is performed using a top-k vote.
* A search is conducted.
* The system determines whether to continue with a check-up.
* The condition "m/k > τ" is present, suggesting a threshold-based decision.
* A statement indicates that mistakes in taking derivatives are rare.
3. **Experience-driven LLM Reasoning:**
* The LLM receives a math question and thinks step by step.
* It identifies a need to recheck derivatives in equation (2).
* Based on the recheck, it determines that further checking is unnecessary.
* The LLM proceeds to the next step and provides a final answer of 204.
* A verification suppression signal is injected.
### Key Observations
* The diagram illustrates a closed-loop system where the LLM learns from its experiences and uses this knowledge to improve its reasoning process.
* The recheck activation detection component plays a crucial role in determining when and how to verify intermediate steps.
* The condition "m/k > τ" suggests a threshold-based decision-making process.
* The injection of a verification suppression signal indicates a mechanism to prevent unnecessary checks.
### Interpretation
The diagram demonstrates a sophisticated approach to improving LLM reasoning by incorporating experience. The LLM learns from past mistakes and successes, allowing it to make more informed decisions about when and how to verify its intermediate steps. This approach can lead to more efficient and accurate problem-solving. The "m/k > τ" condition and the verification suppression signal suggest that the system is designed to balance the need for verification with the desire to avoid unnecessary checks. The final answer of 204 indicates that the LLM is capable of solving mathematical problems using this experience-driven approach.