\n
## Diagram: Experience-driven LLM Reasoning
### Overview
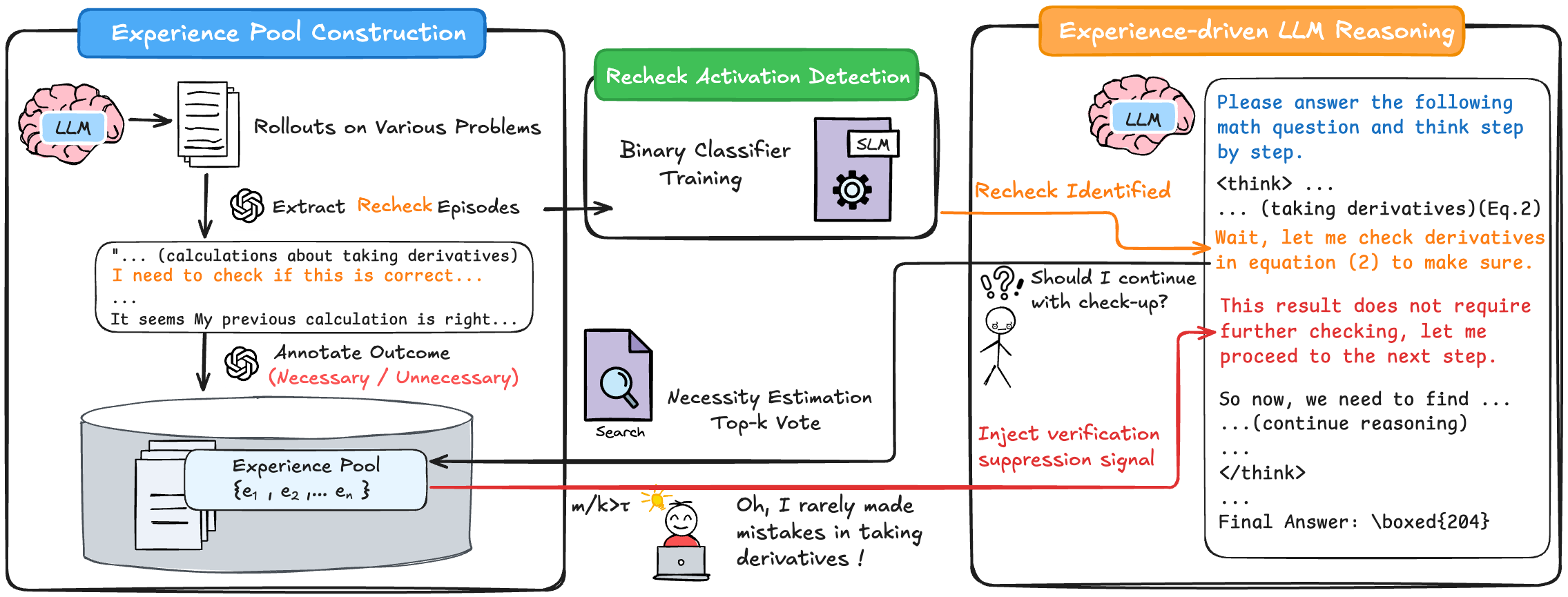
This diagram illustrates a system for enhancing Large Language Model (LLM) reasoning through an "experience pool" and a "recheck activation detection" mechanism. The system aims to improve the LLM's accuracy by identifying when a recheck of its calculations is necessary, based on past experiences. The diagram is divided into three main sections: "Experience Pool Construction", "Recheck Activation Detection", and "Experience-driven LLM Reasoning".
### Components/Axes
The diagram consists of several components connected by arrows indicating the flow of information. Key components include:
* **LLM (Brain Icon):** Represents the Large Language Model.
* **Rollouts on Various Problems:** The LLM generates solutions to different problems.
* **Extract Recheck Episodes:** Identifies instances where the LLM considers rechecking its work.
* **Binary Classifier Training:** A model trained to predict the necessity of a recheck.
* **SLM (Gear Icon):** Likely represents a smaller language model or a specific module within the system.
* **Necessity Estimation (Search Icon):** Estimates the need for a recheck based on a "Top-k Vote".
* **Inject Verification Suppression Signal:** A signal that influences the LLM's decision to continue checking.
* **Experience Pool:** A database storing past recheck episodes and outcomes. Represented as a stack of files.
* **Recheck Identified (Question Mark Icon):** Indicates that a recheck has been triggered.
* **LLM (Reasoning Output):** Shows the LLM's reasoning process, including calculations and final answer.
### Detailed Analysis or Content Details
**Experience Pool Construction (Left Section):**
1. An LLM (brain icon) performs "Rollouts on Various Problems".
2. "Extract Recheck Episodes" captures instances where the LLM expresses a need to verify its calculations. Example text: "...(calculations about taking derivatives)... I need to check if this is correct...".
3. The outcome of the recheck is "Annotate Outcome (Necessary / Unnecessary)". Example text: "It seems my previous calculation is right...".
4. These episodes are stored in the "Experience Pool" represented as {e₁, e₂, ..., eₙ}.
**Recheck Activation Detection (Center Section):**
1. The "Extract Recheck Episodes" feed into "Binary Classifier Training".
2. The trained classifier, represented by an "SLM" (gear icon), detects potential recheck situations.
3. "Necessity Estimation" uses a "Top-k Vote" approach to assess the need for a recheck. A search icon represents this process.
4. A thermometer-like gauge labeled "m/kT" is present, with a character stating "Oh, I rarely made mistakes in taking derivatives!". The gauge appears to indicate a low probability of error.
**Experience-driven LLM Reasoning (Right Section):**
1. The "Recheck Identified" signal triggers the LLM to continue reasoning. A question mark icon represents this.
2. The LLM outputs its reasoning process, including:
* "...(taking derivatives)(Eq. 2)"
* "Wait, let me check derivatives in equation (2) to make sure."
* "This result does not require further checking, let me proceed to the next step."
* "...(continue reasoning)..."
* "Final Answer: \boxed{204}"
**Flow of Information:**
* The flow starts with the LLM generating solutions and potentially identifying recheck episodes.
* These episodes are used to train a binary classifier.
* The classifier, along with necessity estimation, determines whether a recheck is needed.
* A verification suppression signal is injected into the LLM's reasoning process.
* The LLM continues reasoning and provides a final answer.
### Key Observations
* The system leverages past experiences to improve the LLM's reasoning.
* The "m/kT" gauge suggests a confidence level in the LLM's calculations.
* The LLM explicitly states its reasoning process, including when it decides to check its work and when it deems further checking unnecessary.
* The diagram highlights the iterative nature of the LLM's reasoning process.
### Interpretation
This diagram demonstrates a feedback loop designed to enhance the reliability of LLM-based reasoning. By learning from past recheck episodes, the system can predict when the LLM is likely to make mistakes and proactively trigger a recheck. The "m/kT" gauge likely represents a Bayesian probability or similar metric, indicating the confidence in the LLM's current calculation. The system aims to reduce unnecessary rechecks, improving efficiency, while ensuring accuracy by identifying and correcting potential errors. The inclusion of the LLM's internal monologue ("Wait, let me check...") provides insight into the reasoning process and the decision-making criteria for rechecking. The final answer being boxed suggests a definitive result. The system is designed to mimic a human's approach to problem-solving, where experience and intuition guide the decision to verify calculations.